
What Is Hazelcast And What Is It Used For?
Hazelcast serves as a powerful in-memory computing platform, commonly deployed to improve application speed and manage vast amounts of data across clusters.
It excels in distributed caching, real-time processing, and building resilient, scalable systems.
In this article, we break down how developers use Hazelcast in streamlining operations, as well as its core features, and the benefits it brings to data-intensive applications in cloud or enterprise environments.
Key Takeaways
- Hazelcast is an In-Memory Data Grid solution that provides clustering, quick data access, and task distribution, enhancing application performance and scalability through data replication and low-latency operations.
- Hazelcast integrates seamlessly with Spring Boot, enabling distributed data structures and caching to improve application speed. Proper configuration and dependency management are essential for smooth operation and conflict avoidance.
- In constructing scalable applications using Hazelcast, clustering and effective data partitioning ensure high availability, while Near-Cache and custom serialization features allow for improved read performance and optimized data handling.
Understanding Hazelcast: The In-Memory Data Grid Platform
Hazelcast is a robust, open source, in-memory data grid platform that provides distributed data structures and computing utilities for scalable, high-performance data management and processing across a cluster of computers. Hazelcast can run multiple instances of cluster members on the same JVM, allowing for automatic creation and addition of new members to the cluster.
Used by software developers to cluster highly dynamic data with event notifications and manage the distribution of background tasks across multiple nodes, Hazelcast provides a highly scalable solution. It accelerates and scales SaaS or custom internal applications, increasing throughput and reducing data access latency. A single node in a Hazelcast setup can aggregate a high volume of events per second with low latency, showcasing the scalability and performance of the technology.
At its core, Hazelcast operates as an in-memory data grid, leveraging software distributed across a cluster of computers that collectively share their memory for shared data access. It increases data availability and speeds processing by replicating stored data.
Key Features of Hazelcast

Hazelcast comes with a number of distributed data structures, such as multimap, distributed queue, and various other data structures and concurrency primitives. One of its most notable features is Time-To-Live (TTL). It limits the lifespan of an entry in a map to the time since the last write access to the entry, where the config system property is used to set the TTL value for a particular map configuration.
Another notable feature is MaxIdleSeconds, which sets the maximum amount of time each entry can remain in the near cache without being accessed. If an entry is not accessed within this time, it can be flushed from the cache, which is especially useful when working with Hazelcast’s distributed maps.
Hazelcast’s write-through pattern ensures synchronous updates of the in-memory map and the external data store, providing consistency between the two. Hazelcast supports two topologies: Embedded and Client/Server, with Hazelcast members playing a critical role in forming the cluster and managing data distribution.
[Read also: How to Prepare for a Successful System Migration Project]

Hazelcast Architecture
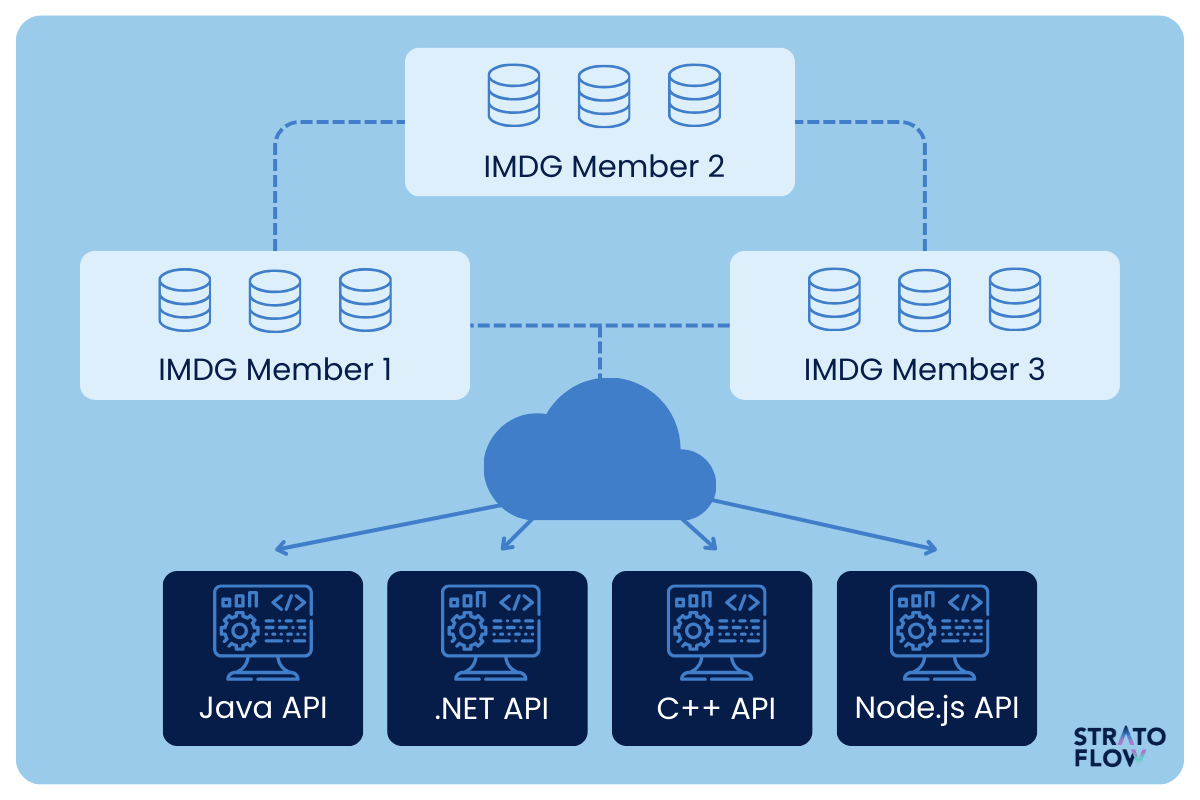
The Hazelcast architecture performs repartitioning when a new member joins or leaves the cluster and assigns data entries to partitions using a hash algorithm.
Cluster members in the Hazelcast architecture serve as compute and storage units, contributing to the communication and data sharing capabilities of the Hazelcast cluster to increase flexibility and performance.
The Hazelcast Management Center can be used to monitor the overall state of clusters, analyze and browse data structures, update map configurations, and take thread dumps from nodes.
Hazelcast uses a replica strategy that evenly distributes primary and backup replicas of partitions across cluster members to maintain redundancy and scalability. Hazelcast ensures data integrity and consistency through the Consistency (CP) subsystem, which is specifically designed for structures that require strict consistency. It also achieves best-effort consistency for less.
Integrating Hazelcast with Spring Boot
The process of integrating Hazelcast with Spring Boot is straightforward, especially since Spring Boot automatically configures Hazelcast for seamless integration. To launch the Hazelcast Management Center and submit a job to a remote Hazelcast cluster, you can use the `hazelcast platform’ command line tool.
Step 1: Adding Dependencies
The first step is to set up a project, add dependencies, and configure Hazelcast. Hazelcast is automatically configured within a Spring Boot application if it is on the classpath and a valid Hazelcast configuration exists.
Integrating Hazelcast with Spring Boot requires the ‘hazelcast-spring’ dependency. This can be added to your Maven or Gradle build files.
You can add the hazelcast-spring dependency to your Maven pom.xml file by adding the following snippet within the <dependencies> section:
<dependencies>
<!-- ... other dependencies ... -->
<dependency>
<groupId>com.hazelcast</groupId>
<artifactId>hazelcast-spring</artifactId>
<version>4.2</version> <!-- Use the latest version applicable -->
</dependency>
<!-- ... other dependencies ... -->
</dependencies>For including the hazelcast-spring dependency in a Gradle build.gradle file, you would add the following line to the dependencies block:
dependencies {
// ... other dependencies ...
implementation 'com.hazelcast:hazelcast-spring:4.2' // Use the latest version applicable
// ... other dependencies ...
}Step 2: Adding Configurations
To configure Hazelcast using the Hazelcast.newHazelcastInstance(createConfig()) method, you generally follow these steps:
- Create a configuration object (typically an instance of Config).
- Customize the configuration settings as needed, which may include defining map configurations, network settings, group configuration, etc.
- Pass this configuration object to Hazelcast.newHazelcastInstance() to create a new Hazelcast instance with your specified settings.
Here is a code snippet illustrating how to configure a Hazelcast instance with custom TTL and Max Idle settings:
import com.hazelcast.config.Config;
import com.hazelcast.config.MapConfig;
import com.hazelcast.core.Hazelcast;
import com.hazelcast.core.HazelcastInstance;
public class HazelcastConfiguration {
public static void main(String[] args) {
HazelcastInstance hazelcastInstance = Hazelcast.newHazelcastInstance(createConfig());
// Use the Hazelcast instance...
}
private static Config createConfig() {
Config config = new Config();
// Create a MapConfig for your map
MapConfig mapConfig = new MapConfig("myMap")
.setTimeToLiveSeconds(360) // Set TTL to 360 seconds
.setMaxIdleSeconds(200); // Set Max Idle to 200 seconds
// Add the MapConfig to the configuration
config.addMapConfig(mapConfig);
return config;
}
}Step 3: Adding Custom Serializer and Data
Adding a custom serializer and controller to interact with the cache data in Hazelcast is critical for performance optimization and effective data management.
Hazelcast uses Java serialization by default, but it’s not the most efficient way to serialize objects because it tends to be slow and produces large serialized forms. A custom serializer can significantly improve Hazelcast’s performance by reducing serialization time and size, which is especially important for distributed systems where data is frequently transferred over the network.
A controller, on the other hand, is typically a piece of your application code that manages cache interactions. It ensures that the cache is used effectively by handling operations such as reading from and writing to the cache, cache invalidation, and synchronization.

Building Scalable Applications with Hazelcast
The construction of scalable applications with Hazelcast requires data clustering for ensuring high availability. Hazelcast’s in-memory grid plays a crucial role in ensuring high availability by:
- Distributing data across multiple nodes
- Distributing data backups across the cluster to prevent data loss in the event of a member failure
- Managing data partitioning and reallocating partition ownerships in response to changes in the cluster membership
Hazelcast can be integrated into a unified real-time data platform to simplify real-time architectures for next-gen applications and AI/ML deployments. This integration modernizes applications, enables instant action on data in motion, and supports new revenue streams while mitigating risk.
Hazelcast provides a plethora of features like distributed caching, synchronization, clustering, and processing that bolster the scalability and high availability of applications. As a fast data store, Hazelcast enhances operational efficiency and supports new revenue streams. Hazelcast developers use Hazelcast to build scalable applications with the ability to prioritize capacity planning, adhere to design principles and coding best practices, and implement efficient performance tuning.
Clustering Data for High Availability
Cluster members within Hazelcast continuously monitor each other’s health to ensure high availability.
If a cluster member becomes inaccessible, the data partition backup is always maintained on another Hazelcast member. Nodes in Hazelcast data clustering are responsible for load balancing data in-memory across the cluster, thus ensuring high availability and scalability.
Managing data loss within a cluster is another crucial aspect of Hazelcast. Strategies such as backing up maps, data replication, and partition backups are implemented to ensure data is preserved on multiple nodes, creating redundancy and mitigating data loss in the event of a node failure. Hazelcast’s data replication and partition backup mechanisms provide robust fault tolerance, ensuring that even if one or more nodes fail, the data remains accessible and consistent across the remaining nodes in the cluster.
[Read also: How to Hire Offshore Developers in 2024: Tips & Trends]
Improving Application Performance with Stream Processing
Hazelcast minimizes latency in applications by utilizing in-memory data storage, resulting in significantly quicker access than disk-based storage. This is achieved through enhanced throughput and application scalability, ultimately leading to reduced data access time.
Hazelcast enhances application throughput by ensuring equitable distribution of load among all nodes in the cluster and having the capability to dynamically manage performance fluctuations and failures. Additionally, Hazelcast’s real-time data processing capabilities allow for immediate insights and actions on streaming data, further optimizing performance and responsiveness.
[Read also: How to Hire Dedicated Developers – Your Ultimate Guide]
Advanced Hazelcast Features
Advanced Hazelcast features offer enhanced capabilities for scalability, frequently used data distribution, messaging, and integration. These features are designed to provide robust solutions for complex distributed computing problems. Here are some of the advanced features of Hazelcast:

High-Density Memory Store (HDMS)
HDMS allows storing larger amounts of data in memory without sacrificing performance, by efficiently utilizing available RAM.
It’s particularly useful for applications requiring a large in-memory dataset, such as caching and in-memory databases. HDMS ensures high performance and prevents Garbage Collection (GC) pauses that can occur with large heaps in Java.
WAN Replication
WAN (Wide Area Network) replication allows setting up Hazelcast clusters in different geographical locations to synchronize data across the globe. This is crucial for disaster recovery and for providing global users with local access points to data, ensuring low latency and high availability.
Hot Restart Persistence
Hot Restart Persistence in the Hazelcast platform provides persistence capabilities for Hazelcast clusters, ensuring that data is not lost when nodes or clusters restart.
It allows for fast recovery by storing the application instances in-memory data state to disk. With Hot Restart, systems can resume operations quickly after planned or unplanned outages.
CP Subsystem
The CP Subsystem provides implementations of strongly consistent data structures and coordination primitives based on the Raft consensus algorithm.
This is crucial for applications that require strict consistency guarantees, such as lock services, leader election, and distributed coordination.
Rolling Upgrades
Rolling upgrades allow for Hazelcast cluster nodes to be updated with new versions without downtime.
This feature is critical for maintaining high availability and ensuring that new features or fixes can be deployed seamlessly in a production environment.
Custom Serialization
Hazelcast client lets you add a custom serializer for the purpose of serializing objects.
Hazelcast offers interfaces such as StreamSerializer and ByteArraySerializer to facilitate this functionality. Custom serialization can be implemented by utilizing the DataSerializable interface, which provides the capability to specify the serialization and deserialization logic for objects.
The process for implementing custom serialization of java objects in Hazelcast using the StreamSerializer interface involves plugging in a custom serializer for serializing your objects.
[Read also: Software Development Process: Comprehensive Guide]
Best Practices for Hazelcast Management Center Deployment
Deploying Hazelcast effectively requires adhering to certain best practices to ensure that the cluster is stable, efficient, and secure. Here are four best practices for Hazelcast deployment:

Properly Size Your Cluster
It’s crucial to appropriately size your Hazelcast cluster based on your application’s requirements for memory, CPU, and network resources.
Over-provisioning can lead to unnecessary costs, while under-provisioning can cause performance bottlenecks or even system failures.
Evaluate your application’s data size, read/write throughput, and latency requirements. Consider the memory overhead for data backups (replicas) and Hazelcast’s internal operations. Monitoring system performance and scaling the cluster (adding or removing nodes) based on demand can ensure optimal resource utilization and maintain the desired performance levels.
Implement Robust Network Configuration
A reliable and secure network configuration is essential for the stable operation of a Hazelcast cluster. Use private networks for Hazelcast nodes to avoid exposure to untrusted networks.
Configure firewalls and security groups to restrict access to the Hazelcast ports, allowing only trusted applications and nodes to communicate with the cluster. Enable SSL/TLS for data-in-transit encryption to protect sensitive data from eavesdropping.
Also, properly configure Hazelcast’s network settings, such as member addresses, port ranges, and the join mechanism (multicast, TCP/IP, or discovery mechanisms like Kubernetes, AWS, etc.), same order to ensure that cluster nodes can discover and communicate with each other efficiently.
Optimize Data Structures and Serialization
Choose the right data structures (e.g., IMap, IQueue, ISet) based on your use case, and configure them with suitable policies for eviction, backup count, and TTL/max idle settings.
Optimize serialization by implementing custom serializers or using compact serialization formats like Avro, Protocol Buffers, or Kryo. This minimizes the size of serialized data and the associated serialization/deserialization overheads, improving overall system performance, especially in network-intensive operations.
Also, consider using Near Cache for frequently read data to minimize latency and reduce the load on the cluster.
Ensure High Availability and Disaster Recovery
Design your deployment for high availability by configuring data replication (synchronous or asynchronous) and backups.
Utilize Hazelcast’s WAN replication feature to synchronize data across multiple clusters in different geographical locations, ensuring that the system can survive regional outages. Regularly back up the cluster state (if using persistence features like Hot Restart) and test your disaster recovery procedures to ensure you can quickly restore operations in case of a system failure.
Employing rolling upgrades and blue-green deployment techniques can help in achieving zero-downtime deployments and maintaining service availability during updates or maintenance.
[Read also: Strangler Pattern for Application Modernization]
Hazelcast and In-Memory Data Grids in Action – Stratoflow Case Study for Financial Institutions
At Stratoflow, our Hazelcast developers have expertise in developing advanced, high-performance in-memory database grid software systems for enterprise applications.
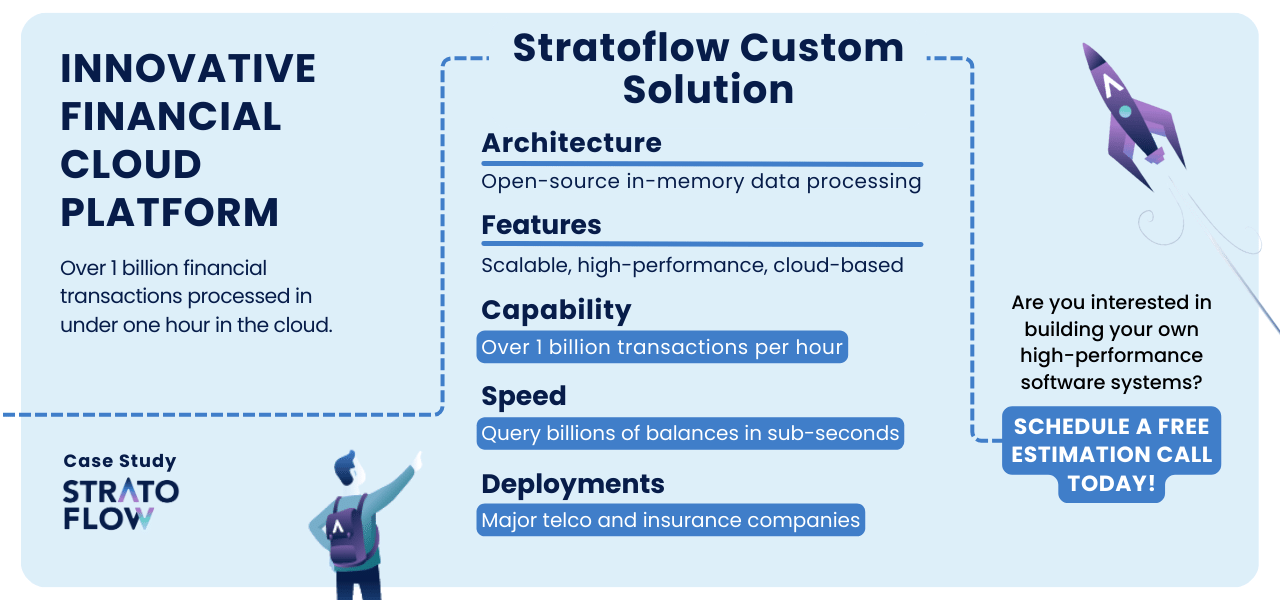
Using the Hazelcast platform we’ve developed a high-performance, horizontally scalable cloud platform for financial applications. The main requirement was to deliver a modern finance platform of outstanding technical capabilities.
Our team of top software development experts created an innovative architecture based on in-memory data processing and open-source solutions was designed to provide a highly scalable, high-performance accounting engine, ledger, and reporting system.
The system is now live and capable of processing in the cloud over one billion financial transactions within an hour and querying billions of balances in sub-second times.
Our approach at Stratoflow combines innovation, engineering excellence, and close collaboration to build scalable data processing systems tailored to a variety of industries.
If you’re looking to develop your own state-of-the-art custom software systems, we invite you to reach out and explore how our solutions can elevate your business! Don’t hesitate and contact us today!

Summary
In conclusion, Hazelcast offers a powerful, scalable, and performant solution for building high-performing applications.
Its key features, architecture, integration with Spring Boot, and advanced features like near-cache and custom serialization make it a versatile tool. With proper network configuration and use of the Management Center, Hazelcast deployment can be optimized for best performance and high availability. As we continue to harness the power of in-memory data, Hazelcast stands out as a game-changer, setting the pace for high-performance computing.
Frequently Asked Questions
What is Hazelcast good for?
Hazelcast is good for implementing caches, managing data across clusters, supporting high scalability and data distribution, maintaining data integrity across multiple applications, and ensuring high availability of data in a distributed environment. It is also useful for real-time data processing and stream processing capabilities.
Where is Hazelcast used?
Hazelcast is widely used across industries by companies like Nissan, JPMorgan, and Tmobile, and is designed for environments requiring low latency, high throughput, horizontal scaling, and security. It can be used for distributed caching, synchronization, clustering, and processing in distributed applications.
How does Hazelcast ensure high availability in applications?
Hazelcast ensures high availability by distributing data across multiple nodes and distributing data backups across the cluster to prevent data loss in the event of a member failure. This approach minimizes the risk of data unavailability and ensures continuous operation of the application.
What is Near-Cache in Hazelcast?
Near-Cache in Hazelcast is a local cache on the client side that improves read performance by storing frequently accessed data close to the application.
Related Posts
Thank you for taking the time to read our blog post!
{kind=link}
{kind=link}