
Movie Recommendation Systems: A Business Guide
In the age of digital streaming, personalized movie recommendations have become a cornerstone of user engagement and satisfaction.
By leveraging advanced algorithms and data analytics, modern streaming platforms can deliver tailored content that keeps viewers engaged and coming back for more.
In this article, we’ll explore the mechanics of movie recommendation systems and provide a step-by-step guide to implementing one in your organization, from data collection and preprocessing to model deployment and continuous improvement.
Improve your platform’s user experience and stay ahead in the competitive streaming market with a robust recommendation system.
Understanding Movie Recommendation Systems
Movie recommendation systems, a subset of AI-powered recommendation systems, are algorithms designed to predict and suggest movies to users based on their preferences and behaviors.
These systems use techniques such as collaborative filtering, content-based filtering, and hybrid methods to analyze user data and generate accurate and relevant recommendations.
Integrated into platforms such as Netflix, Amazon Prime Video, and Hulu, these systems are essential to modern media streaming platforms.
They significantly improve the user experience by reducing the time and effort required to find relevant content.
Their importance in these platforms is underscored by their ability to increase user engagement and retention, providing a competitive edge in a crowded marketplace.

The value of these systems is evident in their impact on business results.
For example, Netflix reported that its recommendation system saves the company approximately $1 billion annually by reducing churn and increasing user engagement.
In addition, the global recommendation engine market size was estimated at $2.12 billion in 2021 and is projected to reach $12.03 billion by 2028, growing at a CAGR of 29.6% during the forecast period.
Do you want to unlock the same technology for your company?
Empower Your Business With AI-Driven Recommendation Engine Today!
The market is also constantly changing and evolving.
Advanced technologies such as deep learning and reinforcement learning are now being integrated into these systems to improve their performance.
For example, deep learning models can understand complex patterns in user behavior and content characteristics, while reinforcement learning optimizes the recommendation process by continuously learning from user interactions.
A movie recommendation engine is a backbone of almost all popular streaming platforms.
Just look at the main page of your Netflix or Hulu account.
The majority of thumbnails are for the shows and movies recommended to you based on your preferences.
These systems enhance user satisfaction by providing personalized content suggestions and support business objectives by keeping users engaged and reducing subscription cancellations but also keep them engaged driving average watch time and time spent in app.
With ongoing advancements in AI and machine learning, these systems are becoming even more effective and essential in the digital media landscape.
Boosting Your Business With Personalized Recommendations
At Stratoflow, we specialize in creating custom, cutting-edge recommendation engines tailored to various industries.
Our expertise lies in harnessing advanced AI and machine learning technologies to develop systems that provide personalized recommendations, enhancing user engagement and satisfaction.

Our extensive experience and deep knowledge in AI and machine learning enable us to create systems that significantly enhance user engagement, customer satisfaction, and conversion rates.
- E-commerce: Enhance customer shopping experiences by providing personalized product recommendations, increasing sales and customer satisfaction. According to a McKinsey report, 35% of Amazon’s revenue is generated by its recommendation engine.
- Media & Entertainment: Deliver tailored content suggestions, such as movies and music, to keep users engaged and boost platform loyalty.
- Finance: Offer personalized financial advice and product recommendations to improve customer retention and satisfaction.
- Healthcare: Provide customized health recommendations and resources to support patient care and wellness.
- Telecommunications: Suggest personalized plans and services to meet individual customer needs and enhance user experience.
- Retail: Optimize complementary products to improve in-store and online shopping experiences, driving sales and customer loyalty.
And of course, media and content streaming platforms!
For the media industry, our recommendation engines deliver precise, personalized content suggestions similar to those used by leading platforms such as Netflix and Spotify.
A custom movie recommendation engine built by our team is designed to revolutionize your business by delivering highly personalized content suggestions that engage your audience.
Using advanced algorithms and machine learning, we analyze user behavior and preferences to recommend movies that match each viewer’s unique tastes.
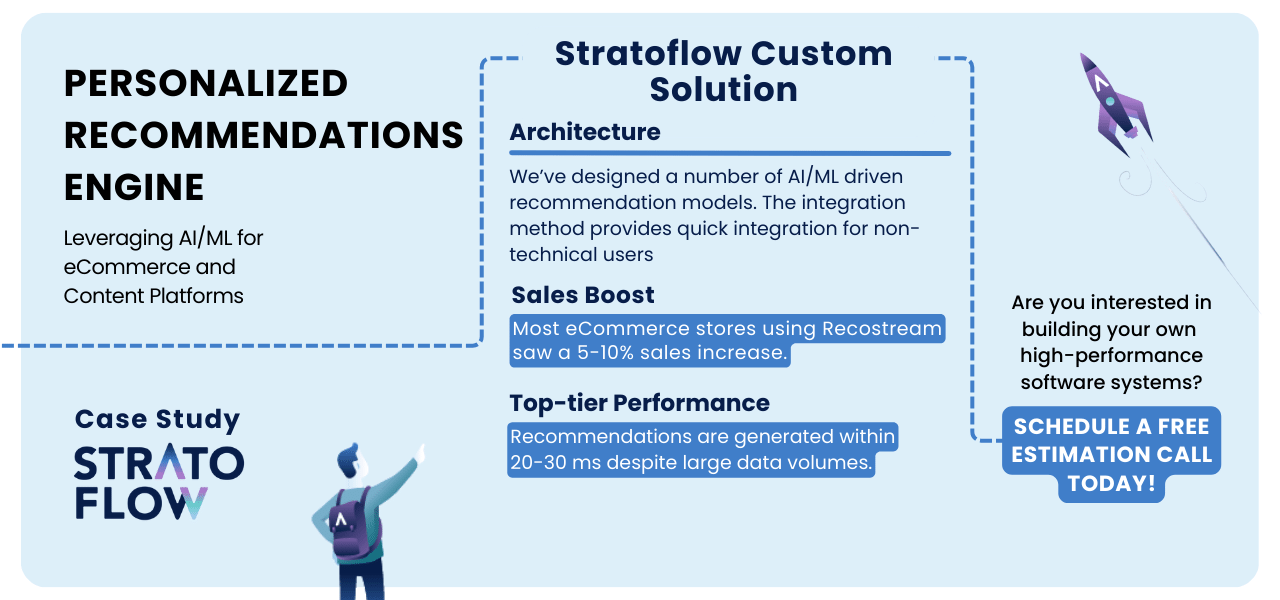
Our extensive experience in building custom recommendation engines is exemplified by our work on Recostream, a sophisticated AI/ML-powered engine. Recostream has proven its effectiveness in the e-commerce space, increasing sales by 5-10% through highly personalized product suggestions.
One of Recostream‘s key strengths is its real-time performance, generating recommendations within 20-30 milliseconds, ensuring a seamless user experience that reduces shopping cart abandonment.
Personalization has become a key trend in modern media, driven by the need to improve user experience and engagement.
At a time when consumers are inundated with a vast array of content options, personalized recommendations help cut through the noise and deliver content that resonates with individual preferences.
A custom recommendation engine can help your business capitalize on this personalization trend. By analyzing user behavior, preferences, and consumption patterns, a recommendation engine can deliver highly relevant content suggestions, ensuring that users spend more time on your platform.
Partnering with us ensures that you benefit from a robust, scalable, and innovative recommendation system that meets your unique business needs and drives both customer engagement and revenue growth.

How Do Personalized Movie Suggestions Work In Practice?
Personalized movie recommendation systems work by collecting and analyzing various types of data to generate tailored recommendations for each user.
The process involves several key steps: data collection, data processing, model training, and recommendation generation.
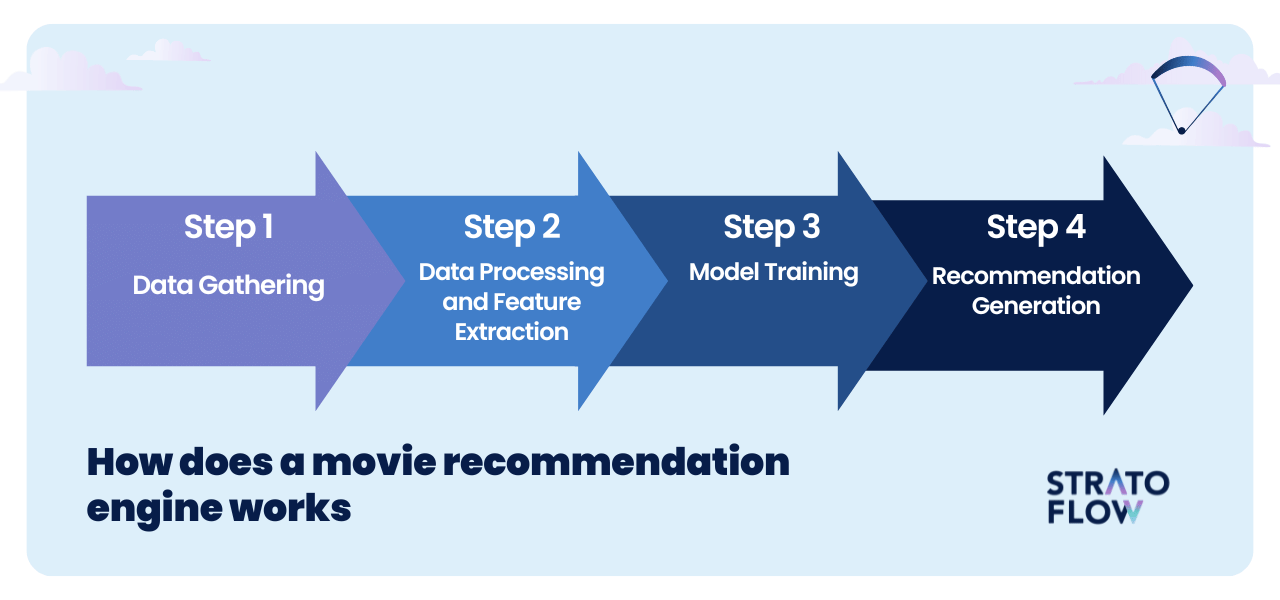
Data Gathering
These systems collect extensive data from users to understand their preferences and behaviors. The types of data gathered include:
- User Interactions: This includes data on movies that users have watched, rated, reviewed, or added to their watchlists. For example, Netflix recommendation system tracks every time a user starts, pauses, rewinds, or finishes a movie.
- Demographic Information: Age, gender, location, and other demographic details can help refine recommendations.
- Viewing Patterns: Time of day, frequency of watching, and duration spent watching certain types of content provide insights into user habits.
- Social Data: Connections and interactions on social media platforms, if integrated, can offer additional context about user preferences.
- Content Data: movie title
Platforms also use tracking technologies such as cookies and web beacons to monitor user behavior in real time.
These technologies track every action a user takes on the platform, including which movies they watch, rate, and add to their watchlists, as well as how they interact with recommendations.
Given the extensive data collection involved in personalized recommendation systems, privacy and ethical considerations are paramount. User consent is a critical issue, as users need to be informed about what data is being collected and how it will be used.
Platforms typically address this through detailed privacy policies and explicit consent forms during the registration process. Ensuring compliance with privacy regulations, such as the General Data Protection Regulation (GDPR), is essential to protect users’ rights and build trust.
Data Processing and Feature Extraction
After cleaning, the next step is feature extraction, which involves identifying and extracting relevant features from the data. Features are the attributes or properties used by the recommendation algorithms to make predictions.
This process includes:
- Removing Inconsistencies: Standardizing data entries to remove duplicates and correct errors.
- Handling Missing Data: Using techniques like imputation to fill in missing values.
- Normalization: Adjusting data to a common scale to maintain uniformity, such as normalizing ratings to a standard scale.
To deal with the high dimensionality of the data, techniques such as Principal Component Analysis (PCA) and Singular Value Decomposition (SVD) are used. These methods reduce the number of features while retaining the essential information, improving the efficiency and performance of the recommendation algorithms.
Once the features are extracted, the data is divided into training and test sets.
The training set is used to train the machine learning models, while the test set is used to evaluate their performance.
Model Training
The first step is to divide the processed data into training and test sets.
Typically, about 70-80% of the data is used for training, and the remaining 20-30% is reserved for testing. This ensures that the model’s performance can be evaluated on unseen data, preventing overfitting and ensuring generalizability.
Then comes another crucial sub-step: selecting the appropriate algorithm.
Common algorithms include matrix factorization methods such as Singular Value Decomposition (SVD) and Alternating Least Squares (ALS), neural networks for deep learning approaches, and ensemble methods that combine multiple techniques for improved accuracy.
During training, the selected algorithm learns from the training data by adjusting its parameters to minimize prediction errors.
After training, the model is evaluated on the test set. Several metrics are used to evaluate performance:
- Precision and Recall: Precision measures the proportion of recommended movies that are relevant, while recall measures the proportion of relevant movies that are recommended.
- F1 Score: This metric is the harmonic mean of precision and recall, providing a single measure of the model’s overall accuracy.
- Root Mean Squared Error (RMSE): RMSE measures the difference between predicted and actual ratings, offering insight into the model’s ability to predict user ratings accurately.

Hyperparameter tuning is the final step in model refinement.
Hyperparameters are settings that are not learned from the data, but are set before the training process begins, such as the learning rate and regularization parameters.
How does all this work in practice?
Netflix, for example, uses a combination of matrix factorization and deep learning do determine movie ratings and to train its recommendation models.
By continuously collecting data on user interactions and updating its models in real time, Netflix is able to provide highly personalized and accurate movie suggestions, increasing user satisfaction and engagement.
Recommendation Generation
After training the models, the final step in a personalized movie recommendation system is to generate and display recommendations to users.
Once the machine learning model is trained, it can generate recommendations in real time by processing current user data.
As users interact with the platform, their behavior (e.g., watching a particular movie, rating content, or adding movies to their watchlists) is continuously fed into the model.
This real-time data ensures that recommendations are as current and relevant as possible.
So how do you best integrate recommendations into a site’s UI?
There’s no single best answer to this question, but there are a few tips to follow.
To effectively integrate movie recommendations into a site’s UI, prioritize placing personalized carousels in high-visibility areas, such as the home page, to immediately capture the user’s interest. Use intuitive and interactive elements such as thumbs up/down and star ratings to gather real-time feedback.
There are also a couple of models showing recommendations to choose from. Most popular of them include:
- Top Picks for You: Curated list tailored to the user’s tastes based on viewing history, ratings, and interactions. Prominently featured on the homepage.
- Because You Watched: Suggestions based on a recently watched particular movie or series. Uses content-based filtering to align closely with recent preferences.
- Continue Watching: Displays shows and movies the user has started but not yet finished, facilitating easy resumption.
- More Like This: Appears when viewing details of a specific movie or show, suggesting similar content based on genre, director, or cast.
- Genre-Specific Carousels: Highlights popular and recommended content within specific genres like “Action,” “Comedy,” or “Documentaries.”
It’s worth noting that in order to maintain high accuracy and relevance, recommendation systems require constant improvement based on new data and user feedback. As user preferences evolve, the system must adapt by incorporating the latest interactions and trends.
Streaming services also regularly conduct A/B testing to experiment with different recommendation strategies and interface designs.
By comparing user engagement across versions, platforms can identify the most effective methods for presenting recommendations and improving user satisfaction.
Key Types of Content Recommendation Engines
Understanding the various types of recommendation engines is crucial for selecting the best approach for your business.
In this section, we will explore the three main types: collaborative filtering, content-based filtering, and hybrid methods, each offering unique advantages for personalized content delivery
Content-Based Filtering
Content-based filtering generates recommendations by analyzing the attributes of items and comparing them to a user’s profile.
This method is based on the concept that if a user has shown interest in a particular movie, he or she is likely to enjoy similar movies with similar attributes.
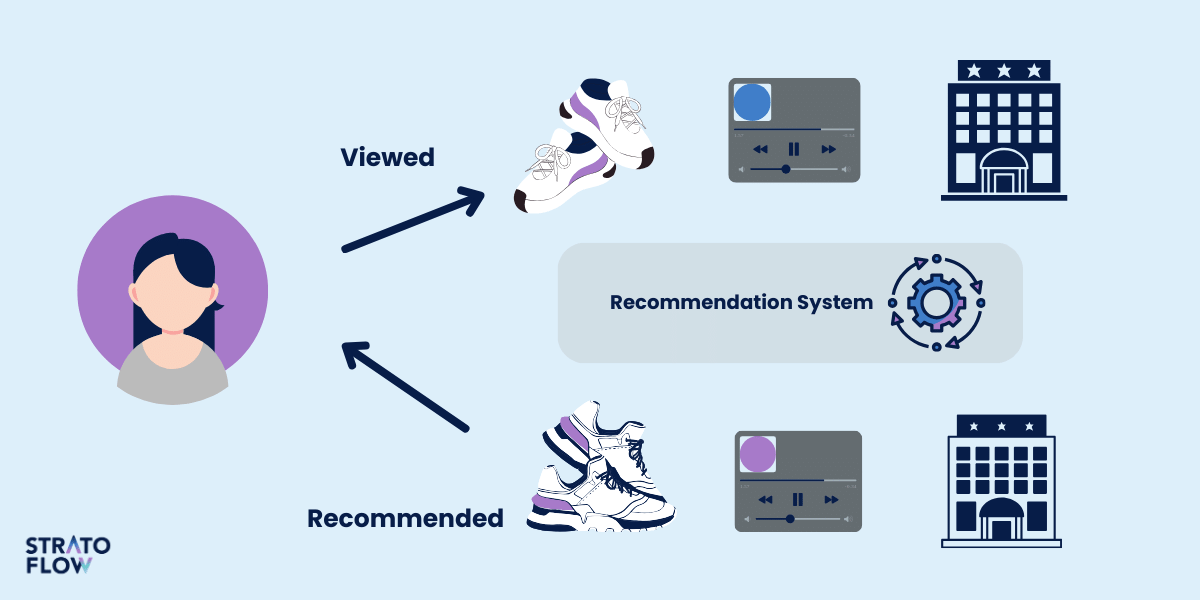
The system first extracts features from movies, such as genre, director, cast, and plot keywords. It then constructs a user profile based on the features of movies the user has positively interacted with.
By calculating the similarity between the user profile and other movies in the catalog, using measures such as cosine similarity or Euclidean distance, the system identifies and recommends movies that closely match the user’s preferences.
Example
If a particular user has watched several science fiction movies starring a specific actor, the system might recommend other science fiction films featuring the same actor or with similar plot elements.
Collaborative Filtering Method
Collaborative filtering algorithms, in contrast, leverages the preferences of multiple users to generate recommendations.
This approach operates on the premise that users who have agreed in the past will continue to agree in the future.
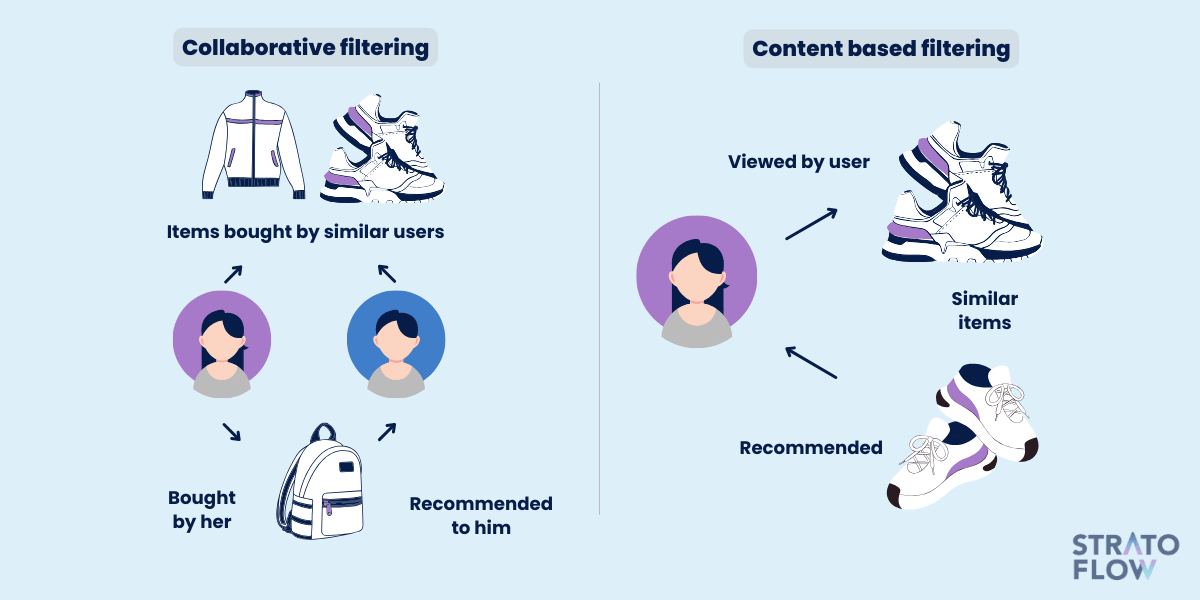
Collaborative filtering can be user-based or item-based. User-based collaborative filtering finds users with similar tastes to the target user and recommends movies that those similar users like.
Item-based collaborative filtering, on the other hand, looks at the similarity between items and recommends movies similar to those that the user has rated highly.
Techniques such as Singular Value Decomposition (SVD) reduce the dimensionality of the user-item interaction matrix to uncover latent factors that influence user preferences.
Example
On platforms like Netflix, if two users have rated many movies similarly, the system might recommend to one user the movies that the other user has highly rated but they have not yet watched.
Hybrid Model Filtering
Hybrid models combine both content-based and collaborative filtering methods to maximize recommendation accuracy and address the limitations of each approach.
These models can integrate predictions from both techniques by using a weighted sum to rank recommendations, or use collaborative filtering to identify a pool of potential movies that are then refined using content-based filtering based on specific user preferences.
Another approach is to dynamically switch between content-based and collaborative filtering based on context or data availability.
Example
Amazon Prime Video employs a hybrid recommendation system where collaborative filtering identifies users with similar tastes, and content-based filtering refines the recommendations by analyzing the attributes of items those users have liked.
This ensures that recommendations are both diverse and closely aligned with the user’s interests, offering a more comprehensive and engaging user experience.
[Read also: How to Introduce Product Recommendations in Your Business]
How To Build a Custom Movie Recommendation System? 8 Key Steps
Building on our understanding of the key types of recommendation engines, we can now dive into the practical process of developing a custom movie recommendation system.
This section outlines the 8 essential steps, from data collection to model deployment and continuous improvement, providing a comprehensive guide to enhance your streaming platform’s user experience.
Step 1: Define the Problem and Objectives

Before launching into the development of a custom movie recommendation engine, it is critical to clearly define the problem and establish the goals of the project.
This first step sets the stage for all bigger custom software development projects and ensures that the development effort is focused on the desired outcomes.
Determining the type of recommendation system-whether collaborative filtering, content-based, or a hybrid approach – is essential to guide the design and implementation process.
Establishing these objectives early on will help in scoping the project, selecting appropriate algorithms, and identifying necessary data, ultimately leading to a more focused and successful development process.
Sample Java-Based Tech Stack
- Programming Language: Java
- Framework: Spring Boot
- Database: MySQL, MongoDB
- Data Processing: Apache Spark
- Machine Learning Library: Apache Mahout, Weka
- API Development: Spring MVC, Spring REST
- Dependency Management: Maven
- Version Control: Git
- Continuous Integration: Jenkins
- Containerization: Docker
- Deployment: AWS, Kubernetes
Step 2: Data Collection

When developing a custom movie recommendation system, selecting effective data collection methods is critical.
Batch and real-time processing are the primary methods used to collect and manage the data needed for accurate recommendations.
These pipelines extract data from multiple sources, transform it into a consistent format, and load it into the system’s database. Tools such as Apache Spark are invaluable for efficiently handling large-scale data aggregation and transformation.
In contrast, real-time processing focuses on ingesting and processing data as it is generated.
Event streaming platforms such as Apache Kafka enable the continuous collection of user interactions, such as ratings and views, to ensure that the recommendation engine has the most up-to-date data.
Data Ingestion
Data ingestion is the process of importing, transferring, and loading data from various sources into the recommendation system’s database.
One of the most common methods of data ingestion is through APIs and web scraping. APIs from platforms such as IMDb, TMDb, and OMDb can be integrated to pull rich movie data directly into the system.
Step 3: Data Preprocessing

Data preprocessing is a crucial step in developing a custom movie recommendation system, as it prepares the raw data for analysis and modeling.
This process involves cleaning, transforming, and organizing data to ensure it is in the optimal format for building accurate and efficient recommendation algorithms.
Here a few tips to efficiently prepare your data for recommending new movies to other users:
Tips for Effective Data Preprocessing
- Automation: Automate the data preprocessing pipeline using tools like Apache Airflow or Prefect to ensure consistency and reproducibility.
- Documentation: Maintain thorough documentation of all preprocessing steps to facilitate debugging and future modifications.
- Data Quality Checks: Implement regular data quality checks and validation processes to detect and correct issues early.
[Read also: Online Shopping Recommendations – How to Introduce Them in Your Business?]
Step 4: Exploratory Data Analysis (EDA)

Exploratory Data Analysis (EDA) is a critical step in the development of a custom movie recommendation system.
It involves analyzing and visualizing data to uncover patterns, identify anomalies, and test hypotheses. EDA helps understand the structure, distribution, and relationships of the data, and guides further data preprocessing and feature engineering steps.
Initial Data Inspection
This step involves loading your datasets into Java data structures for initial inspection. Typically, you will have datasets containing movie metadata (such as titles, genres, directors), user data (user IDs, demographics), and user interactions (ratings, viewing history).
It is important to use robust libraries such as Apache Commons CSV or OpenCSV to read CSV files into Java objects such as lists or maps.
After loading the data, examine its structure to understand the types and distributions of the variables you’re dealing with.

Data Visualization and Hypothesis Testing
Data visualization is a critical aspect of exploratory data analysis (EDA), which involves using graphical representations to understand data distributions, relationships, and patterns. Three primary methods are used: Univariate Analysis, Bivariate Analysis, and Multivariate Analysis.
Based on domain knowledge and initial observations, you develop hypotheses about the data.
For example, you might hypothesize that “higher-rated movies are more likely to be in certain genres. Formulating hypotheses helps guide your analysis and focus on specific questions that need to be answered to build a more accurate recommendation system.
You can then use statistical tests to validate your hypotheses.
For example, you can run t-tests to compare the means of ratings between two genres, or use ANOVA to compare ratings across multiple genres.
Based on these findings, you can move on to building models that will work best in your particular scenario.
Step 5: Model Selection

After completing the initial data analysis and exploratory data analysis (EDA), the next step in building a movie recommendation system is to select the appropriate model.
While we have already discussed the different types of recommendation engines – collaborative filtering, content-based filtering, and hybrid approaches-in detail, this section focuses on determining which model is best for your specific use case and how to implement it effectively.
Steps for Model Selection
The first task is to define the evaluation metrics that will be used to assess the performance of your recommendation models.
Choosing the right metrics is critical because they guide the evaluation and comparison of different models. Common metrics include Mean Absolute Error (MAE), which measures the average size of errors in predictions and is useful for continuous rating predictions, and Root Mean Squared Error (RMSE), which emphasizes larger errors by measuring the square root of the average squared differences between predicted and actual values.
Establishing a baseline model is an important next step.
A simple approach might be to recommend the most popular movies to all users.
This involves calculating the most frequently rated or highest rated movies and recommending them to everyone. Evaluating the performance of this baseline model using the chosen metrics provides a reference point against which more complex models can be compared.
Example Workflow
- Baseline Model: Recommend the top 10 most popular movies to all users and evaluate using precision and recall.
- Collaborative Filtering: Implement user-based collaborative filtering using k-NN and item-based collaborative filtering using matrix factorization (e.g., SVD). Evaluate both models using RMSE and select the better-performing one.
- Content-Based Filtering: Extract features from movie metadata (e.g., genre, director) using TF-IDF vectorization, train a content-based recommender using cosine similarity, and evaluate using precision and recall.
- Hybrid Approach: Combine collaborative and content-based models using a weighted hybrid method, tune the weights to balance the contributions of each model, and evaluate using F1 score and AUC-ROC.
- Final Model Selection: Compare the hybrid model with the best individual models and select the model offering the best balance of accuracy, scalability, and ease of integration.
Step 6: Model Training

Having completed the initial data analysis, exploratory data analysis (EDA), and model selection, we now move to the critical step of model training.
In this step, the pre-processed data is used to train the selected recommendation model and optimize it to make accurate and relevant predictions.
Training Process
The training process begins by dividing the data set into training and test sets, typically using an 80:20 or 70:30 split.
This ensures that the model can be evaluated on unseen data to measure its performance. The training set is used to teach the model patterns and relationships within the data, while the test set helps validate its predictive power.
It is critical to ensure that the split is random and maintains the distribution of scores to avoid bias.
Hyperparameter Tuning and Evaluation
After training the initial model, hyperparameter tuning is essential to optimize its performance.
Hyperparameters are the external configurations of the model that must be set before learning begins, such as the number of latent factors in matrix factorization, the number of neighbors in k-NN, or the regularization parameters.
Tuning these hyperparameters involves finding the best combination that maximizes the performance of the model.
This can be done by grid search, which tests all possible combinations within a given range, or by random search, which randomly samples a subset of combinations and is often more efficient for large hyperparameter spaces.
Step 7: Model Evaluation

Model evaluation is a crucial step in the development of a movie recommendation system. It involves assessing the performance of the trained model to ensure that it provides accurate and relevant recommendations.
Performance Evaluation
The first step in model evaluation is to apply these metrics to evaluate the model’s performance on the test set. By calculating metrics such as MAE, RMSE, Precision, Recall, F1 Score, and AUC-ROC, you get a quantitative measure of the model’s accuracy and relevance.
This helps to understand how well the model performs in making predictions and identifying relevant items for users.
Next, applying cross-validation techniques ensures the robustness of the model and helps prevent overfitting. In k-fold cross-validation, the data set is divided into k subsets.
The model is trained on k-1 subsets and validated on the remaining subset. This process is repeated k times, with each subset used once as the validation set.
Error analysis is another important part of model evaluation.
By analyzing the errors, you can understand where the model performs well and where it falls short. For example, you can identify consistent patterns of under- or overestimation of ratings, or you can see that the model is failing to recommend certain types of movies.
Step 8: Model Deployment And Continuous Improvement

The final step in developing a custom movie recommendation system is model deployment and continuous improvement.
The first step is to set up the necessary infrastructure for deployment. This includes preparing servers and databases and leveraging scalable cloud platforms such as AWS, Google Cloud, or Azure.
The use of containers and orchestration tools, such as Docker and Kubernetes, can facilitate smooth scaling and management of the deployment process.
Once the model is deployed, thorough testing and validation is required to ensure that it works correctly in the production environment.
Continuous monitoring is essential to maintain and improve the performance of the model. Implement monitoring tools and dashboards to track key performance metrics such as response time, accuracy, and user engagement.
It is also important to implement a feedback loop that collects user feedback and interaction data, such as ratings, clicks, and viewing history, to gain insight into the model’s effectiveness. Performing A/B testing allows you to compare different versions of the model to optimize performance.
[Read also: AI Recommendation Engine – How Artificial Intelligence is Transforming Modern Businesses]
Conclusion
Implementing a powerful movie recommendation system is a complex and challenging project that requires expertise in data analysis, machine learning, and software development.
Given these difficulties, partnering with a specialized custom software development company like Stratoflow can significantly streamline the process.
Leverage their expertise to transform your business and delight your audience with personalized recommendations.
Related Posts
- Online Shopping Recommendations – Introducing Them to Your Business
- Amazon Product Recommendation System: How Does Amazon Algorithm Work?
- How to Build a Recommendation System: Explained Step by Step
- 10 Best Custom Insurance Software Development Companies in 2026
- How to Build an Inventory Management System: Key Steps and Tips
Thank you for taking the time to read our blog post!
{kind=link}
{kind=link}