
How to Build a Recommendation System: Explained Step by Step
In 2024 recommendations engines are standard functionality in every ecommerce and travel website.
Whether you’re a tech enthusiast, a novice developer, or a curious business owner, our easy-to-follow guide will walk you through the process of choosing or building your own recommendation engine.
From collecting data to implementing it into your platform, we’ve got you covered.
Contents
- What is an AI-powered recommendation system?
- Types of Recommendation Systems
- How Recommender System Work
- Building Machine Learning Recommendation System: Custom Solution Crafted By Experts
- Step-By-Step Process to Build a Recommendation System Using Machine Learning
- How to choose the right recommendation engine
- Why go for a custom recommendation engine
- What industries use recommendation systems?
What is an AI-powered recommendation system?
An AI-powered recommendation system is an intelligent technology used by businesses to suggest products, services, or content to users based on their preferences.
Imagine a digital assistant that learns what you like by looking at your past choices and the preferences of others like you.
This is the core concept behind intelligent recommender systems.
Recommendation engines use sophisticated algorithms and statistical models to predict and present users with items, services, or content that match their interests and preferences. Such systems are prime examples of how AI, is leveraged here and there in 2024 to drive sales and user engagement.
Recommendation system: statistics and value
You might not have put much thought into it but when you shop online, watch movies on a streaming service, or browse TikTok, you interact with intelligent recommendation systems basically all the time.
The recommendation engine market is expected to reach USD 15.13 billion by 2026, and it was valued at USD 2.12 billion in 2020, registering a CAGR of 37.46% during the period of 2021-2026.
Around 71% of e-commerce sites offer product recommendations. Research from Salesforce shows that shoppers who click on recommendations are 4.5x more likely to add these items to their cart and 4.5x more likely to complete the purchase. A study by Monetate found that shoppers who engaged with a recommended product had a 70% higher conversion rate during that session.
Types of Recommendation Systems
There are actually a number of ways to generate personalized content recommendations, depending on the type of data we base our predictions on and how we process that data.
Let’s look at four of the most important:
Collaborative filtering
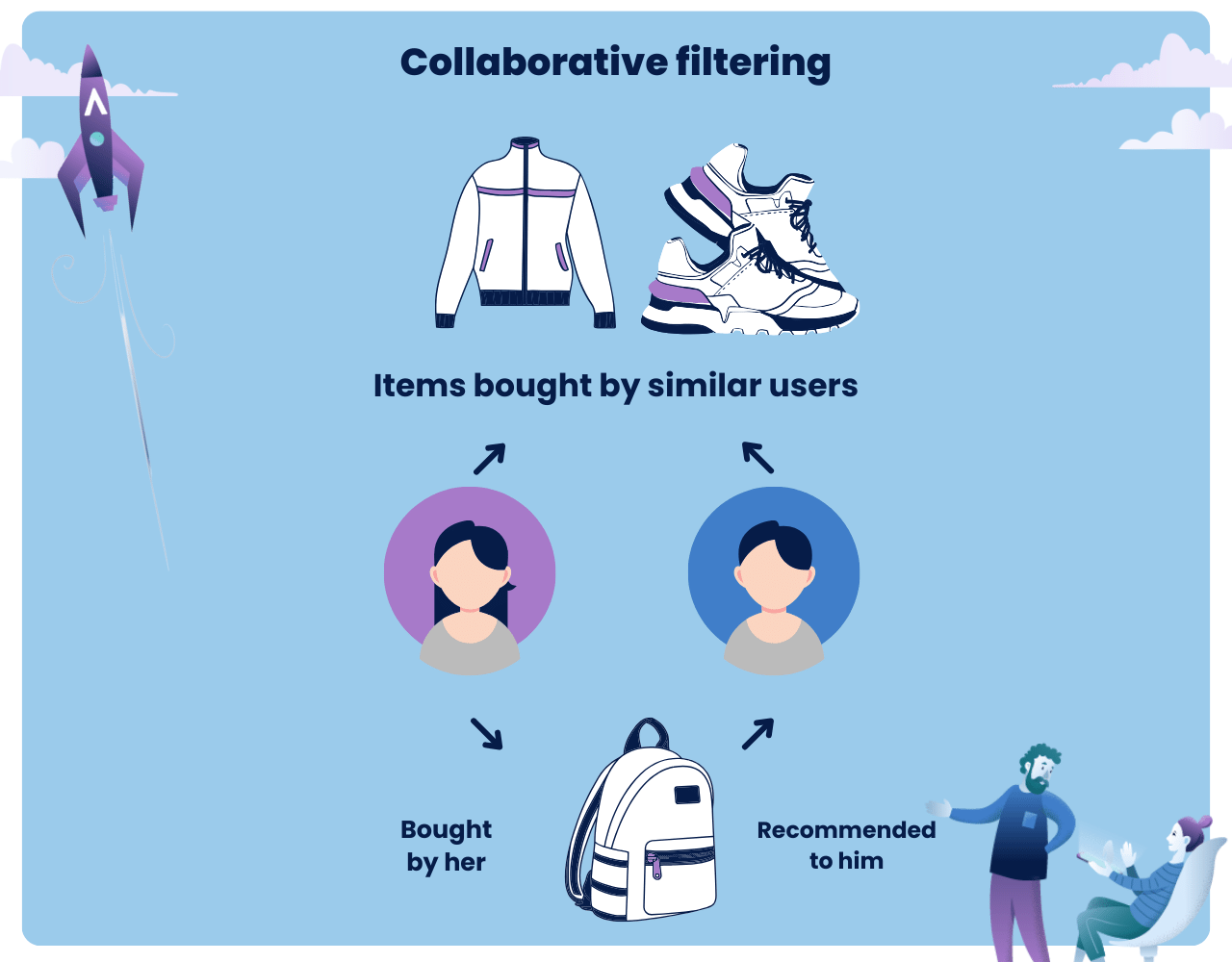
The collaborative filtering model is a popular method used in AI-based recommendation systems.
It works by collecting and analyzing information about users’ behaviors, activities, or preferences, and predicting what they will like based on the preferences of other, similar users.
Think of it as a digital form of word-of-mouth: if a group of people liked both A and B, then someone who liked A might also like B.
Collaborative filtering algorithms rely heavily on collecting and examining user data. For example, in case of movie recommendation system, in a movie streaming service, collaborative filtering would look at the movies you’ve watched and compare them to what others have watched. If you and another user liked many of the same movies, the system would recommend movies that the other user liked but you haven’t seen.
The key idea here is that users who have agreed in the past will agree in the future.
Content based filtering
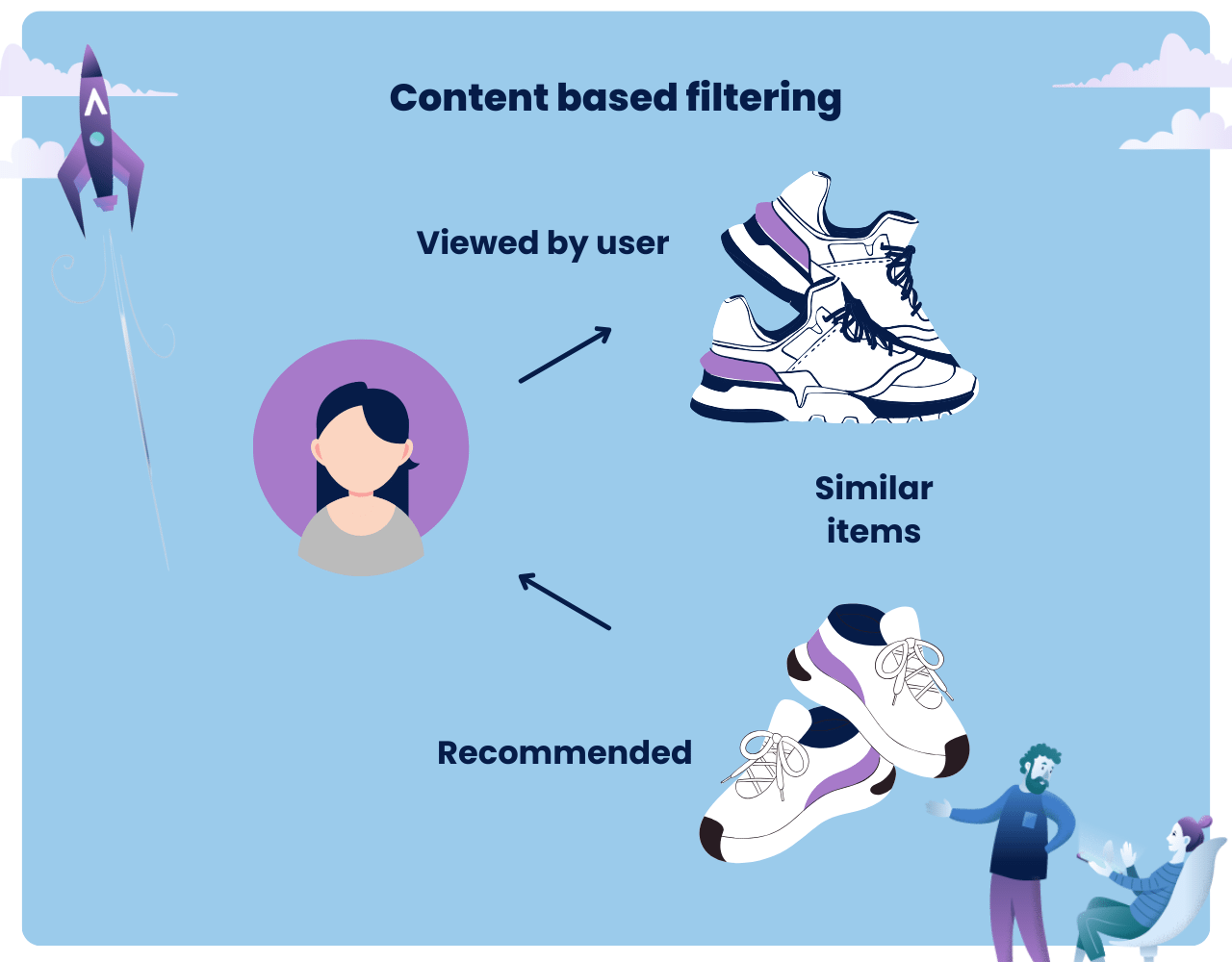
Content-based filtering is another key method used in AI-powered recommendation systems, focusing on the characteristics of the items themselves rather than on user behavior patterns.
This approach recommends products or content by understanding the characteristics of the items and matching them to a user’s profile.
For example, in a book recommendation system, content-based filtering looks at the attributes of books you’ve enjoyed in the past-such as genre, author, user ratings, or keywords-and then finds other books with similar attributes.
If you’ve read and enjoyed several science fiction novels, the system will suggest other books in the science fiction genre.
The user profile is the key to this method. It’s built based on the choices and preferences you’ve shown through your past actions, such as the items you’ve viewed, purchased, or rated highly.
The more you interact with items, the better the system understands what you like and the more accurate the recommendations become.
However, content-based filtering can sometimes limit the variety of recommendations because it tends to suggest items that are very similar to what you already know and like, potentially missing out on suggesting different but relevant items.
Hybrid recommendation systems
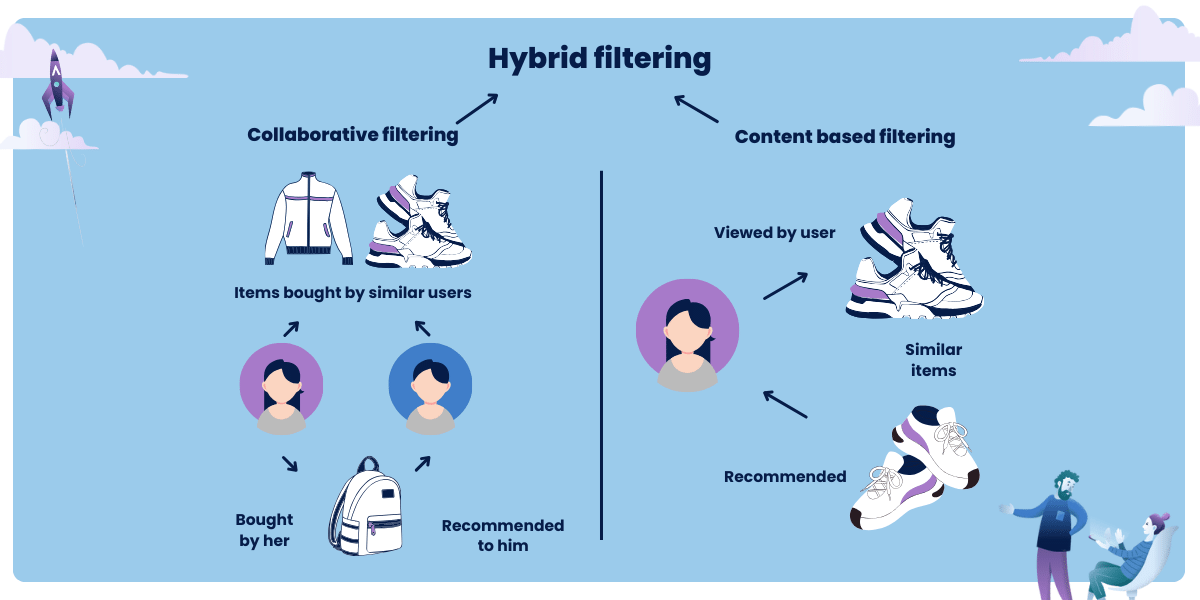
Hybrid recommendation systems combine the best of collaborative and content-based filtering to provide more accurate and diverse suggestions.
This approach combines insights from user behavior (like collaborative filtering) and the characteristics of the items themselves (like content-based filtering) to make recommendations.
The hybrid approach is particularly effective because it can overcome the limitations of each method. It can provide more personalized recommendations than collaborative filtering alone, which may be too general, and it can provide a wider range of suggestions than content-based filtering, which may be too narrow. By combining these methods, hybrid systems can provide a more balanced and comprehensive recommendation experience.
Deep learning-based recommendations
Deep learning and machine learning recommendation systems are advanced types of recommendation engines that use deep learning techniques, a subset of artificial intelligence (AI) that mimics the workings of the human brain in processing data.
These systems are capable of handling complex and large-scale data to provide highly personalized recommendations.
In a deep learning recommendation system, layers of algorithms, called neural networks, analyze vast amounts of data, learning intricate patterns and relationships within the data.
For example, in an e-commerce platform, such a system can analyze not just your past purchases and views but also more subtle factors like how long you look at an item, the sequence of your browsing, and your interactions with various product features.
These systems based on the machine learning model are particularly powerful because they can understand and utilize a wide range of data types, including text, images, and user interactions, to create a comprehensive user profile and item descriptions.
This ability allows them to provide highly accurate and personalized recommendations that are not just based on explicit preferences, but also on explicit feedback and nuanced patterns in the data.
How Recommender System Work
Curious about the inner workings of recommender systems?
This section provides a step-by-step breakdown of this fascinating process.
From the initial data collection to the final presentation of recommendations, you will understand how these systems expertly analyze data and transform it into personalized item suggestions.
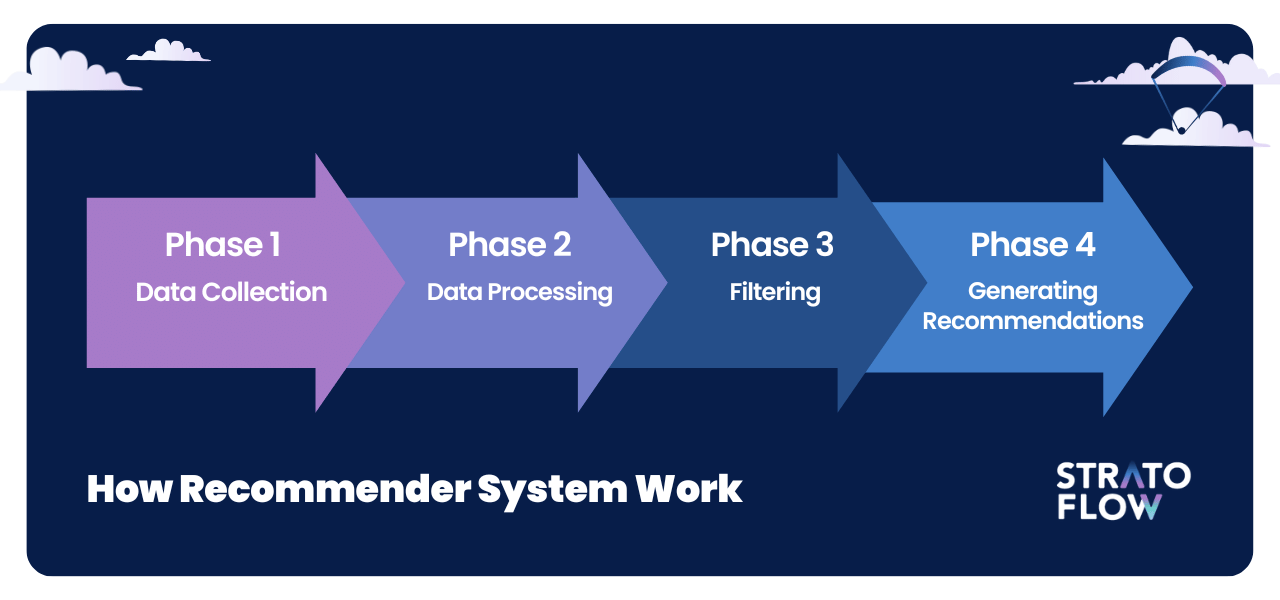
Phase 1: Data Collection
During this initial phase, the engine collects a wide range of data, including user interactions (such as clicks, views, or purchases), user demographics (such as age and location), and detailed item information (such as descriptions and categories). A challenge in this step, known as the “cold start problem,” occurs when there is insufficient data on new users or items, making it difficult to provide accurate recommendations initially.
In the data collection phase of a recommendation engine, various methods are used to gather comprehensive information.
One of the primary tools used is Web crawlers, which are automated programs that navigate the Internet to collect data from various Web sites. They are particularly useful for gathering detailed information about items such as product descriptions, customer reviews, and ratings.
In addition, user information is collected through techniques such as the use of cookies. Cookies are small files stored on users’ devices that track their visits to and interactions with websites. This allows the recommendation system to understand user behavior on the site by tracking actions such as clicks, views, and purchases. Together, these methods provide a rich data set that forms the basis for generating accurate and personalized recommendations.
Here are the types of data collected by recommendation systems:
- User Behavior Data: This includes data on the actions users take, such as the items they view, purchase, or add to their wishlist. It also tracks the frequency of these actions and the time spent on each item.
- User Demographic Data: This refers to personal information about the user, like age, gender, location, and possibly income level or educational background.
- Item Data: This encompasses details about the products or content available for recommendation, such as descriptions, categories, price, brand, specifications for products, or genre and author for books.
- Contextual Data: It includes information about the context in which user interactions take place, such as the time of day, season, or whether the interaction was on a mobile device or a desktop.
- Feedback Data: User ratings, reviews, and preferences explicitly provided by the users are also vital. This data helps in understanding the user’s satisfaction and preferences more directly.
Phase 2: Data Processing
The second step in the functioning of a recommendation engine is data processing, a critical phase in which the collected data is refined and prepared for analysis.
This step is all about ensuring the quality and usability of the data.
First, data cleansing is performed to remove irrelevant, incomplete, or erroneous information. This may involve filtering out noise or correcting data inconsistencies to ensure that the remaining data is accurate and reliable.
Next, data transformation is performed to convert the raw data into a structured format suitable for analysis.
This can include normalizing data (scaling it to a certain range), categorizing unstructured data (such as text or images), and creating user or object profiles.
Another key aspect is data integration, where data from different sources is combined to create a comprehensive view. For example, users’ demographic data can be merged with their behavioral data. Finally, feature extraction is critical, where specific attributes or “features” are identified and extracted from the data.
These features, such as the frequency of item views or the types of products viewed, are what the recommendation algorithms will later use to make predictions.
Overall, data processing transforms raw, unorganized data into a clean, structured format that is essential for the recommendation engine to function effectively.
Phase 3: Filtering
At this stage, methods such as matrix factorization are used.
Matrix factorization is a mathematical technique for predicting user preferences. It works by breaking down a large user-item interaction matrix into smaller, more manageable matrices representing users and items. These matrices are then used to identify latent factors that influence user preferences.
By applying specific mathematical recommendation algorithms, the system can predict how likely a user is to prefer an item, even if they haven’t interacted with it before.
Phase 4: Generating Recommendations
The fourth step in the operation of a recommendation engine is the generation of recommendations, a crucial phase in which the processed data and the insights gained from the previous steps are used to suggest relevant items or content to the user.
In this stage, the engine applies algorithms to predict and match user preferences with available items to provide personalized and relevant suggestions.
The engine considers factors such as past user behavior, similarities between items, and user profiles to generate these recommendations.
In making these recommendations, the engine strives to balance relevance, user engagement, and business goals, such as promoting new products or increasing sales in certain categories.
The ultimate goal is to enhance the user experience by providing timely and relevant suggestions that are tailored to the user’s needs and interests.
What are these types?
Let’s look at what many e-commerce sites are doing with their recommendations:
- Personalized Recommendations: A recommender tool tailored specifically to an individual’s preferences and past behavior, these suggestions are based on items the user has previously interacted with, showing similar or complementary products.
- Best Sellers: These are popular items across the platform, often recommended to new users or those with limited interaction history. They represent what is trending or most purchased in a certain category.
- Related Items: Often seen as “Customers who viewed this also viewed” suggestions, these are based on the correlation between products, recommending items that other users have looked at or purchased in relation to the current item.
- New Arrivals: Recommendations focusing on the newest items in a category, useful for returning users to discover the latest products or content.
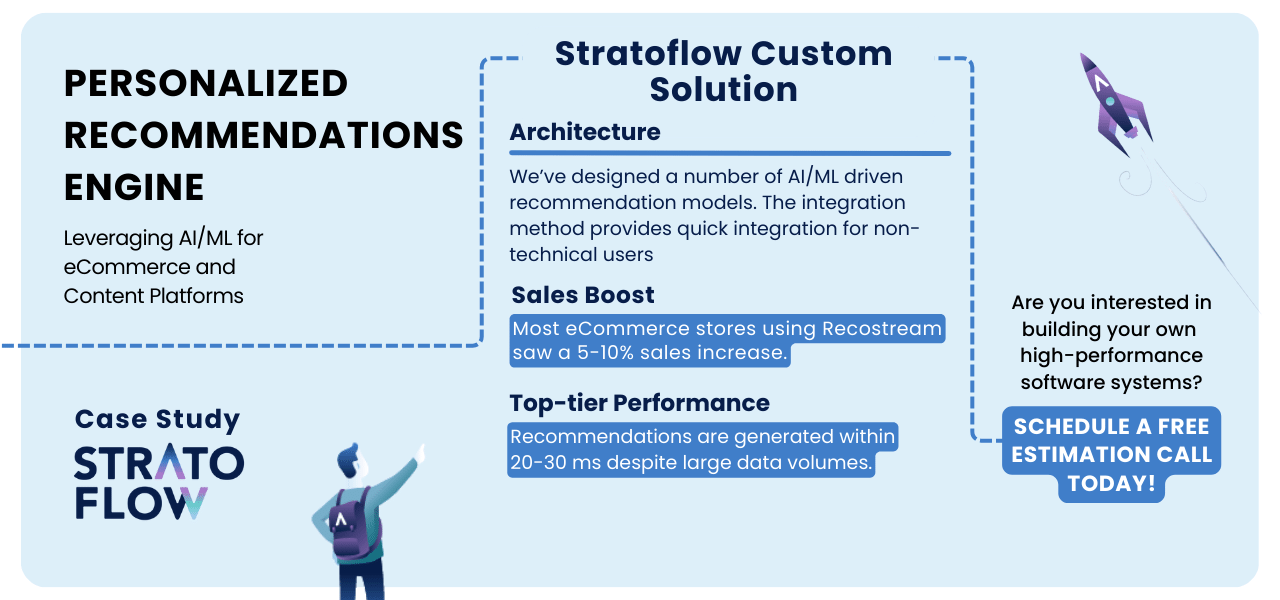
Building Machine Learning Recommendation System: Custom Solution Crafted By Experts
So you want to build a recommendation engine.
It may seem simple at first, but there are a lot of things that go into providing users with relevant recommendations in a sufficiently short time.
One of the main difficulties is accurately understanding and predicting user preferences. Each user has unique tastes and behaviors that can vary widely.
The challenge is compounded by the sheer variety of products available in a typical online store. With potentially thousands or even millions of items, the recommendation engine must sift through this vast inventory to find the most relevant options for each user.
Also critical is the speed at which these recommendations must be generated. In the context of an online store, the user experience is paramount, and any delay can lead to frustration and abandonment. Recommendations must be delivered in milliseconds to maintain a seamless and responsive browsing experience.
Step-By-Step Process to Build a Recommendation System Using Machine Learning
Let’s now share a little glimpse of your process and share broad steps we take to build a custom recommendation system leveraging machine learning from the ground up.
From the initial stages of collecting and processing data and the development planning phase to the final touches of integrating and deploying your system, each step is critical to creating a tool that not only understands but also anticipates the needs and preferences of your users.
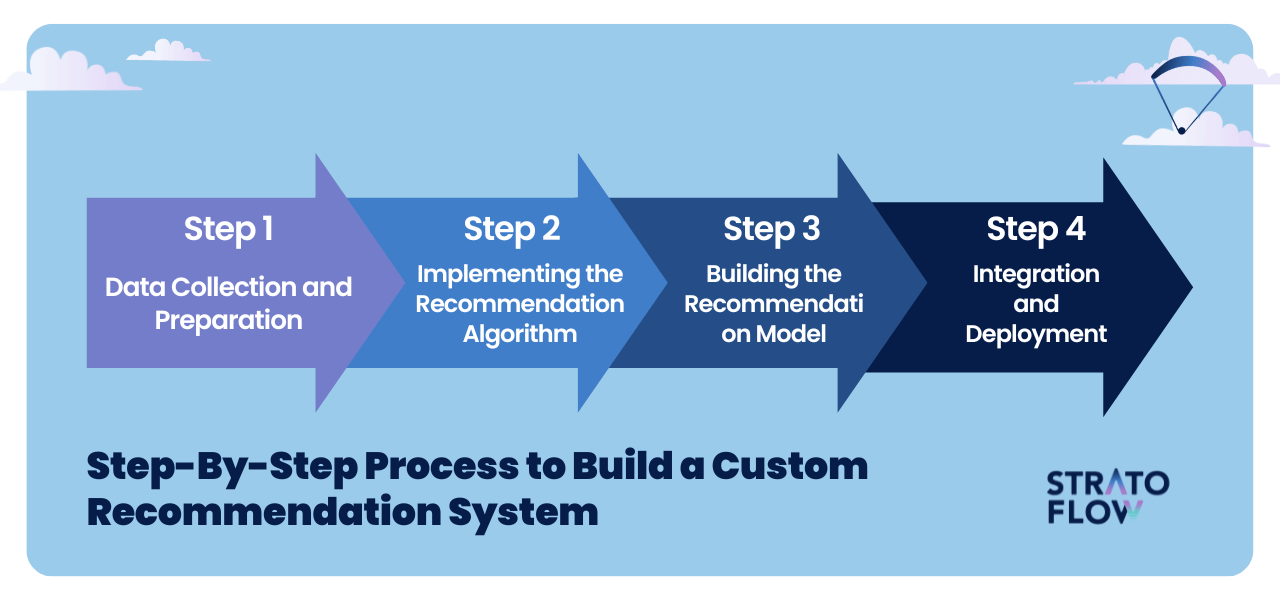
Step 1: Data Collection and Preparation

The foundation of a recommendation system is robust data.
Begin by collecting relevant data, which may include user interaction data (clicks, views, purchases), user demographic data (age, location, preferences), and item attributes (product descriptions, categories, ratings).
This data can be sourced from APIs, databases, or web scraping.
Web Scraping
Web scraping involves programmatically accessing web pages to extract data. This is typically done by parsing the HTML content of the page to retrieve specific data such as product details, prices, reviews, or user-generated content.
In Java, there are several libraries and frameworks available for web scraping. Jsoup is a popular choice, known for its ability to parse HTML and extract data.
Another option is HtmlUnit, which is more like a headless browser and can handle JavaScript-rendered content. Apache HttpClient can be used to make HTTP requests to retrieve web pages, which can then be parsed using Jsoup or similar libraries.
To build a web scraper in Java, you’ll start by making a request to a web page using Apache HttpClient or a similar tool.
Once you have the HTML content, you’ll use Jsoup to parse the HTML and extract the data you need.
It’s important to respect the site’s terms of service and robots.txt file when scraping. It is also important to manage the rate of your requests to avoid overloading the server.
Data Processing
Once the data is collected, the next critical step is data pre-processing. This involves cleaning the data to remove inaccuracies or missing values and transforming it into a structured format, such as CSV or JSON, that can be easily processed.
Data normalization (to put all data on a common scale) and categorization (especially for unstructured data such as text) are important aspects of this step.
Data normalization is the process of transforming data to a common scale, which helps to compare and analyze data that was originally in different formats or scales. This is especially important in recommendation systems where different types of data need to be compared.
Common techniques include min-max normalization, where values are scaled to a range between 0 and 1, and z-score normalization, where data points are scaled based on their mean and standard deviation. The choice of method depends on the nature of the data and the specific requirements of the recommendation algorithm.
There are three general best practices for data normalization:
- Consistency: Apply the same normalization technique across all similar data types for consistency.
- Handling Outliers: Be mindful of outliers in your data, as they can skew the normalization process. Sometimes, it might be necessary to handle outliers separately.
- Reversibility: In some cases, you might want to reverse the normalization process to interpret the results. Ensure that the normalization process you choose is reversible.
Step 2: Implementing the Recommendation Algorithm

Choosing the right algorithm is critical.
When implementing the algorithm, the nuances of each approach must be considered. Each offers unique advantages and works better in different scenarios, but in most cases, the hybrid approach that combines elements of both approaches is the best choice.
Collaborative Filtering
When choosing a recommendation algorithm, you may want to consider collaborative filtering.
As we’ve already explained, this method makes recommendations based on the collective preferences of other users.
Item-based collaborative filtering models can be further divided into user-based and item-based approaches. User-based focuses on finding similar users, while item-based looks for relationships between items.
Speaking of collaborative filtering, it’s worth mentioning matrix factorization.
It works by decomposing the user-item interaction matrix into lower-dimensional matrices representing latent factors. Matrix factorization uses techniques such as Singular Value Decomposition (SVD) or Alternating Least Squares (ALS). These methods identify underlying patterns in user-item interactions by reducing the dimensions of the data, making it easier to predict missing values.
Matrix factorization is particularly effective with sparse data sets and can improve the quality of recommendations by capturing the underlying structure in the data.
One challenge is choosing the right number of latent factors, as too few can oversimplify the model, while too many can lead to overfitting.
Content Based Filtering
There are also content-based methods that recommend items, such as a particular movie, by comparing the content (attributes, descriptions) of the items themselves. If a user likes a certain item, the recommendation system shows items with similar characteristics. It relies heavily on extracting features from the items, which can be text-based (like keywords in a book description) or based on other item attributes.
In Java, these algorithms can be hand-coded (by no means an optimal approach) or implemented using libraries such as Apache Mahout (a much more desirable approach), which provides a set of pre-built algorithms and tools for building recommendation systems.
When implementing the algorithm, the nuances of the chosen approach must be taken into account. If you’re using collaborative filtering, you’ll need to create a matrix of user-item interactions. For content-based filtering, item attributes must be converted into a machine-readable format. Libraries like Mahout greatly simplify this process with built-in functionality.
Data Filtering in Recommendation Algorithms:
- Explicit vs. Implicit Data Filtering: Explicit data filtering uses clear user inputs like ratings or reviews. Implicit data filtering relies on indirect measures of user preference, like browsing history or purchase behavior.
- Memory-Based vs. Model-Based Approaches: Memory-based approaches use the entire user-item dataset to generate a recommendation and are straightforward but can be inefficient with large datasets. Model-based approaches, on the other hand, involve building a predictive model, which can handle large datasets more efficiently.
Step 3: Building the Recommendation Model

The first task is to train your recommendation model on the processed data.
This involves feeding your data into the chosen algorithm and allowing it to learn from the data patterns and user preferences. This process involves the algorithm learning from the data, identifying patterns, and understanding relationships between different variables. The training process differs depending on whether you’re using collaborative filtering, content-based filtering, or a hybrid approach.
After you’ve trained your model, it’s important to validate its performance. This is typically done by dividing your data set into a training set and a test set. The model is trained on the training set and then tested on the test set to evaluate its accuracy and effectiveness.
Common validation metrics include:
- Precision: Precision measures the proportion of recommended items that are relevant to the user. In the context of a recommendation engine, if the system suggests 100 items and 90 of them are actually interesting to the user, the precision is 90%. High precision indicates that the recommendations are generally relevant and useful.
- Recall: Recall, on the other hand, assesses the proportion of relevant items that were actually recommended by the system. For instance, if there are 100 items that should be of interest to a user but the system only recommends 70 of them, the recall is 70%. High recall implies that the system is effective in identifying a large number of relevant items for each user.
- Mean squared error: Mean Squared Error is a common measure in predictive models, including recommendation systems. It calculates the average of the squares of the errors or deviations (i.e., the difference between the predicted values and the actual values). In recommendation systems, it can be used to measure the accuracy of predicted ratings. Lower MSE values indicate better model accuracy.
- A/B testing: A/B testing involves comparing two versions of the recommendation model to see which performs better. In this approach, you would typically have a control group (A) and a test group (B). Each group is exposed to a different version of the recommendation algorithm. The performance of each version is then evaluated based on user engagement or other relevant metrics. This method is particularly useful for practical, real-world validation of the recommendation system.
Based on the performance in the testing phase, the model may need to be tuned. This may involve adjusting parameters, refining the algorithm, or even revisiting the data processing step to ensure that the data is optimally prepared for the model.
In Java, tuning can be a process of trial and error and may require a deep understanding of the underlying algorithms and the characteristics of your data.
Building a recommendation model in Java requires careful consideration of the type of model, the nature of your data, and the specific needs of your application. It requires a blend of technical Java skills and an understanding of machine learning concepts to ensure that the model is accurately trained, validated, and optimized for best performance.
Step 4: Integration and Deployment

The final step in building a custom recommendation engine, Integration and Deployment, involves embedding the developed system into an existing application or platform and ensuring that it operates effectively in a real-world environment. This phase is critical because it transforms the recommendation model from a standalone entity into a functional component of a larger system.
API-Based Integration
One of the most common methods for integrating a recommendation engine with a web application is through an Application Programming Interface (API). In this approach, the recommendation engine is hosted as a separate service, and the web application interacts with it via API calls.
When a user interacts with the web application (like browsing products or watching videos), the application sends a request to the recommendation engine’s API with relevant user data. The engine processes this request, generates recommendations, and sends them back as a response to the API call, which the web application then displays to the user.
Embedding as a Microservice
Another approach is to integrate the recommendation engine as a microservice within the application’s architecture. This means the engine operates as an independent but connected part of the larger system, often communicating with other services through internal APIs or message queues.
Microservice architecture offers scalability and flexibility, allowing the recommendation service to be scaled independently of the rest of the application, which is beneficial for handling varying loads and updating the recommendation logic without affecting other services.
Direct Integration
For smaller applications or in cases where the recommendation engine is not expected to handle a high volume of requests, it can be directly integrated into the web application’s codebase.
This approach involves embedding the recommendation logic and model directly within the application’s server-side code. While this method offers simplicity and direct control, it can be less scalable and might complicate updates to the recommendation logic.
Deployment
It’s important to ensure that the deployment strategy accounts for the expected load. This involves not just handling a large number of requests but also managing the computational load associated with processing these requests, especially for complex algorithms.
After deployment, continuous monitoring is essential to ensure the system’s performance and availability. This includes tracking system health, user engagement, and the accuracy of recommendations.
Regular updates and maintenance are also crucial. The recommendation engine might need retraining with new data, algorithm adjustments, or tuning to adapt to changes in user behavior or product offerings.
[Read also: Netflix Algorithm: How Netflix Uses AI to Improve Personalization]
Benefits of using AI-powered recommendation systems
How such a system can influence your recommence business?
Based on our experiences with Recostream let’s cover all of the key benefits that stem from integrating personalized recommendations.
From improving the user experience with customized suggestions to increasing sales and customer retention, AI recommendation engines are not just a technology trend, but a game-changer across multiple industries.

Increased Sales
First and foremost recommendation engines increase sales by suggesting relevant products or services to users.
By displaying items that customers are more likely to be interested in, these systems increase the likelihood of purchase. This tailored approach can lead to an increase in average order value as customers find more items that meet their needs or desires.
The Epsilon research report highlights that personalization is a key factor in consumer preferences, with 80% of consumers showing a preference for brands that offer personalized experiences. This suggests that personalization can be a significant competitive advantage for companies seeking to increase customer loyalty and satisfaction.
Improved Customer Experience
Personalized recommendations enhance the user experience by making it easier for customers to find products or content that match their interests.
This personal touch makes the browsing experience more engaging and satisfying, leading to increased customer satisfaction and loyalty.
Higher User Engagement
By presenting users with items that match their preferences and interests, recommendation engines encourage longer and more frequent interactions with the platform.
This increased engagement can lead to more time spent on the site, more pages viewed, and a higher likelihood of return visits.
Efficient Discovery of Products
For users, navigating through a vast array of products or content can be overwhelming.
Tens of categories, thousands of products to choose from, and multiple customization options – ask yourself why e-commerce sites sometimes have high bounce rates and abandoned carts. In a lot of cases, it’s because users cannot navigate your site efficiently.
Recommendation engines help with efficient discovery by filtering and suggesting items relevant to the user’s tastes, simplifying the search process and improving discoverability.
Data-Driven Insights
These engines provide valuable insights into customer behavior and preferences. By analyzing the data collected, businesses can gain a deeper understanding of their audience, which can inform marketing strategies, inventory decisions, and even product development.
Increased Customer Retention
Personalized recommendations contribute to building a more satisfying user experience, which can foster customer loyalty. When customers feel that a platform understands their preferences, they are more likely to return and continue using the service.
Competitive Advantage
Utilizing a recommendation engine can give businesses a competitive edge. In a marketplace where many options are available, the ability to offer personalized recommendations can be a differentiator that attracts and retains customers.
Optimized Inventory Management
By analyzing trends and preferences, recommendation engines can aid in predicting demand for certain products. This insight allows for more effective inventory management, ensuring that popular items are well-stocked and less popular items are not over-ordered.
How to choose the right recommendation engine
Choosing the right recommendation engine involves several key considerations to ensure it is a good fit for your business needs.
How do you choose among the multiple recommendation systems currently on the market? Let’s find out!
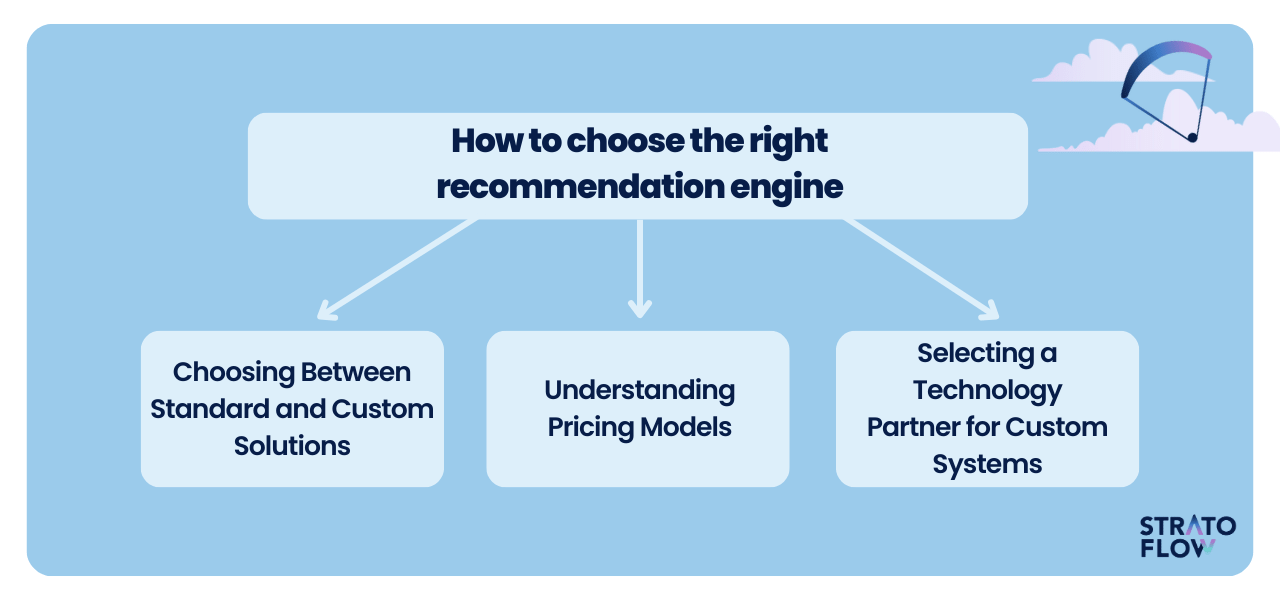
Choosing Between Standard and Custom Solutions
When choosing a recommendation system, weigh the pros and cons of an out-of-the-box system versus a custom software development approach.
Off-the-shelf solutions offer quick integration, while custom systems are tailored to your unique business needs, providing greater flexibility and specificity.
Understanding Pricing Models
For standard recommender systems, thoroughly understand the pricing structure.
This could vary from charges per user to fees based on the number of recommendations made. Aligning this with your company’s financial strategy is crucial.
Selecting a Technology Partner for Custom Systems
If a custom solution is your choice, carefully select your tech partner.
Assess their technical expertise, industry experience, portfolio relevance, and the success metrics of their past projects to ensure they can deliver a system that meets your business needs effectively and efficiently.
[Read also: Essential Reading: 7 Best Books & 4 Research Papers on Machine Learning Recommender Systems]
Think outside of the box: why go for a custom recommendation engine
Choosing a custom recommendation engine can be a transformative strategic decision for an organization, offering a number of benefits tailored to its unique needs.
First, a custom engine is designed specifically for your business, taking into account the nuances of your products, services, and customer demographics to deliver a level of personalization that off-the-shelf solutions can’t match.
This results in an enhanced customer experience with recommendations that are finely tuned to individual preferences, increasing customer loyalty and the likelihood of repeat business. Such personalization can also give your business a competitive edge by capitalizing on unique market insights and opportunities that generic systems may miss.
In terms of adaptability, custom engines offer scalability and flexibility, allowing them to evolve with your business and continually meet changing needs.
Finally, investing in a custom recommendation engine is more than just an operational upgrade; it’s a long-term strategic investment that positions your company for sustainable growth and success, making it a critical part of a forward-looking, data-driven business strategy.
What industries use recommendation systems?
Recommendation systems are widely used across industries, leveraging technology to improve business strategies and customer experiences.
Here’s a look at some of the key industries where these systems are being used prominently:
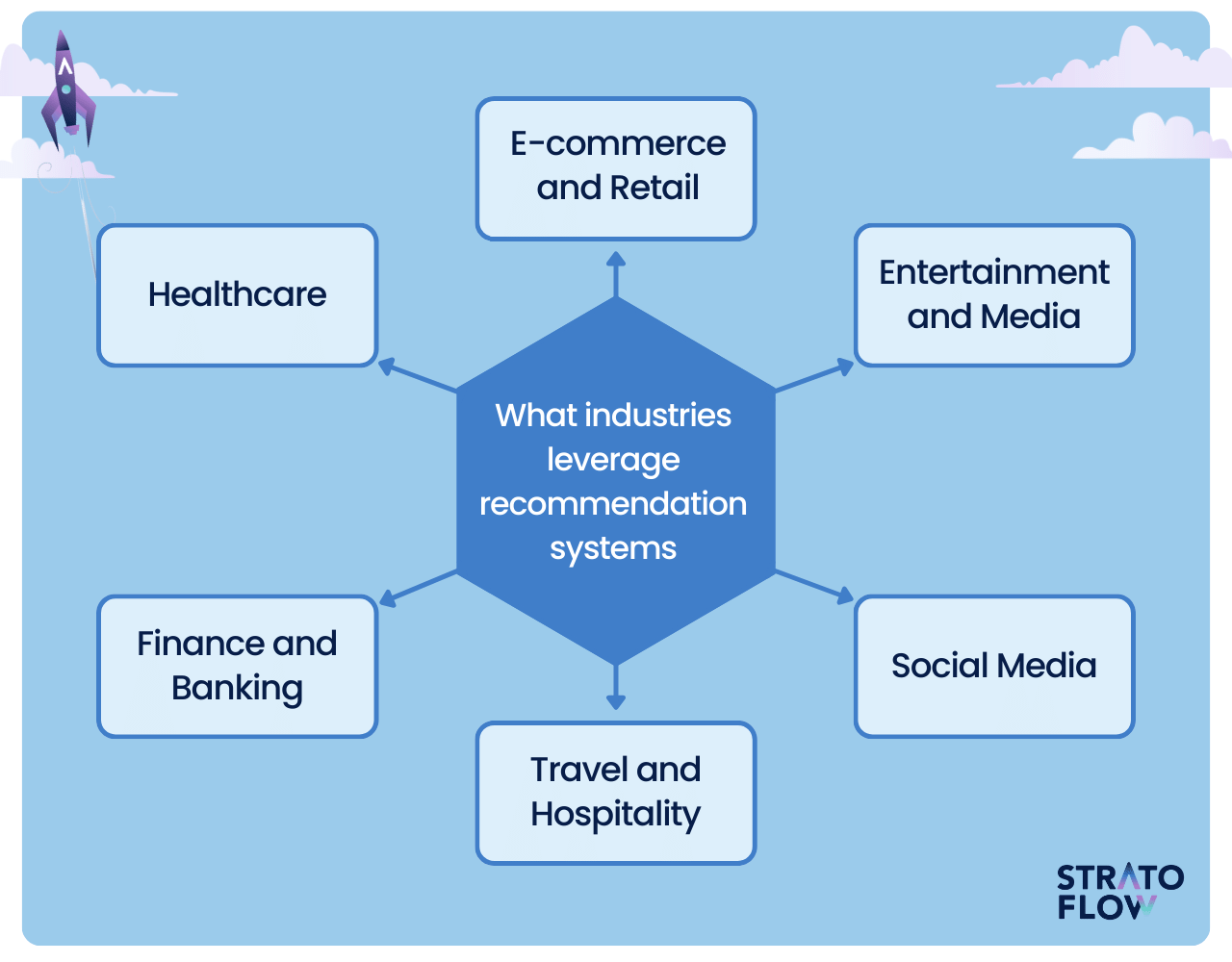
E-commerce and Retail
Online shopping platforms like Amazon use recommendation systems to suggest products to customers. Based on your browsing history, previous purchases, and what other customers have bought, the system shows items you might like. This helps businesses increase sales and improve customer engagement.
Entertainment and Media
Streaming services like Netflix or Spotify use these systems to recommend movies, TV shows, or music. By analyzing, using the user movie rating matrix, what you’ve watched or listened to before, along with preferences of users with similar tastes, the system offers personalized content, keeping viewers and listeners engaged.
Social Media
Platforms like Facebook or Twitter use recommendation engines to suggest friends, pages, groups, or content. By understanding your interactions and connections, these systems enhance user experience by showing more relevant and engaging content.
Travel and Hospitality
Websites for booking hotels, flights, or holiday packages often use recommendation systems. These systems suggest destinations, hotels, or travel plans based on your past searches and bookings, making it easier to find trips that suit your preferences.
Finance and Banking
Recommendation systems in banking might suggest credit cards, investment options, or saving plans based on your financial history and behavior. They help personalize financial services, making them more relevant to individual customers.
Healthcare
In healthcare, these systems can recommend personalized treatments or health plans based on patient history and similar cases. This helps in providing tailored healthcare solutions.
Conclusion
And there you have it – your journey through the world of building recommendation systems, demystified step by step!
With these insights, you’re now equipped to embark on your own adventure in tailoring technology to fit your unique needs.
Remember, the power of a well-crafted recommendation system can revolutionize the way you engage with your audience or streamline your services. So, go ahead, put this knowledge into action, and watch as your project transforms from concept to reality. The future of personalized experience is in your hands!
Related Posts
- Online Shopping Recommendations – Introducing Them to Your Business
- Amazon Product Recommendation System: How Does Amazon Algorithm Work?
- Movie Recommendation Systems: A Business Guide
- Types of Recommendation System For Business Growth: Your Guide
- An In-Depth Guide to Machine Learning Recommendation Engines
Thank you for taking the time to read our blog post!
{kind=link}
{kind=link}