
Using Java for Data Science: Features and Frameworks
Machine learning, AI, and big data are transforming business operations, but which technologies are best for large, data-intensive projects?
Java, often praised for its versatility and scalability in software development, is an underrated powerhouse in data science. With its robust ecosystem and seamless integrations, Java can unlock advanced data processing capabilities.
In this article, we explore Java’s role in data science and how to leverage it for maximum performance.
Why use Java for data science?
While Python has long been hailed as the language of choice for data science and statistical analysis, the Java programming language is a compelling alternative for several reasons.
First and foremost, Java’s reputation for stability and scalability makes it an ideal choice for large-scale data processing and enterprise-level projects. With its strong typing system and strict syntax, Java provides robust error handling and seamless integration with existing Java-based systems.
In addition, Java offers a wide range of libraries and frameworks designed specifically for data analysis, such as Apache Hadoop and Apache Spark, which provide powerful tools for distributed computing and parallel processing.
Additionally, Java performance, just-in-time (JIT) compilation, and Java Virtual Machine platform independence enable efficient execution of compute-intensive tasks, making it well-suited for scenarios where speed and resource in database management are critical.
By leveraging these strengths, data scientists can harness the power of Java to tackle complex data challenges with precision and reliability.
5 reasons why Java is a great programming language for data science
Since we’ve already answered the question of why use Java for data science, let’s compile this information into a comprehensive list of 5 key reasons why this programming language is a safe choice for data-intensive tasks.
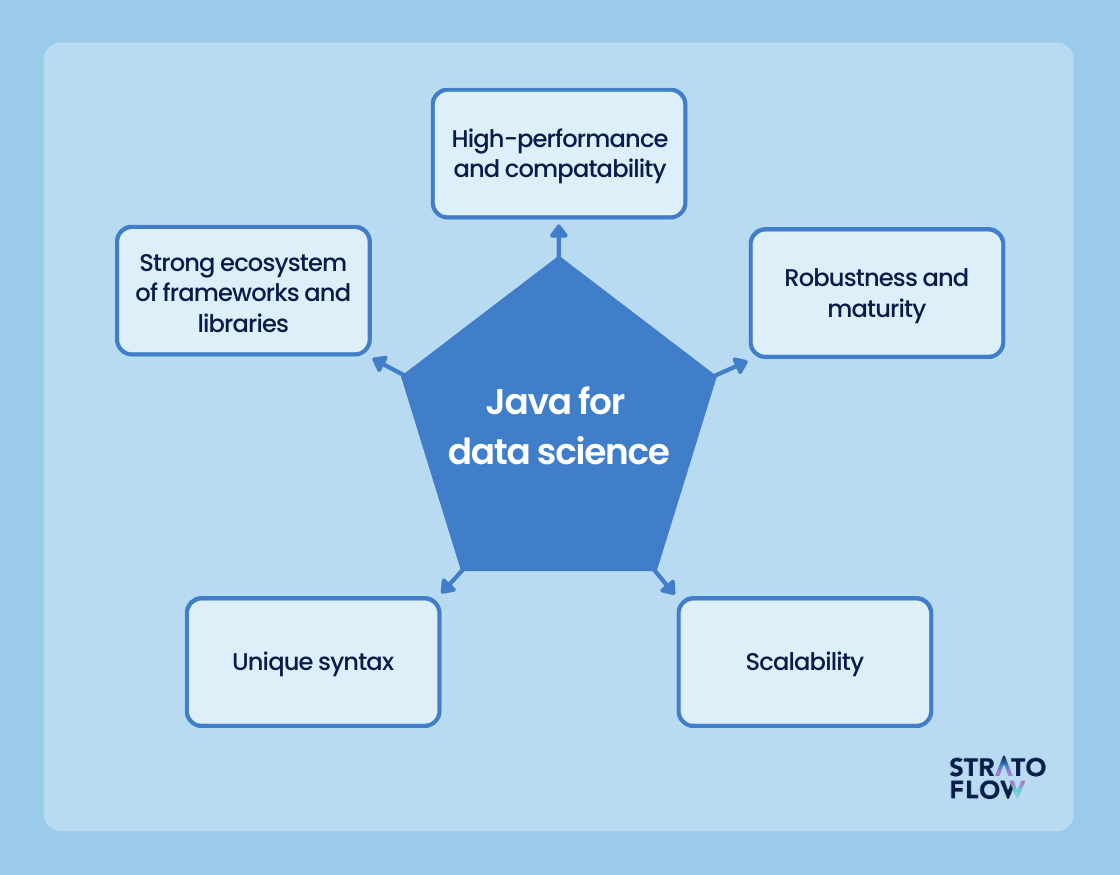
Strong ecosystem of tools and libraries
Java’s robust ecosystem needs no introduction. After all, it’s one of the language’s greatest strengths, and that extends to data science as well.
Java’s libraries and frameworks, such as Apache Hadoop, Apache Spark, and Weka, provide powerful tools for distributed computing, big data processing, and machine learning, making Java a versatile choice for data scientists.
High-performance and compatibility
Java’s architecture and bytecode execution make it highly scalable and efficient. It leverages the power of the Java Virtual Machine (JVM) to optimize performance and latency, allowing data scientists to process large datasets and run CPU-intensive algorithms quickly and reliably. Many developers will be surprised to learn that Java is up to 25 times faster than Python, another contender for the title of data science programming king.
Java is also highly functional in many data science processes such as data analysis, including data import, data cleaning, statistical analysis, natural language processing (NLP), and data visualization.
Robustness and maturity
With over 30 years on the market, Java is a mature and incredibly popular programming language with a strong emphasis on reliability, stability, and backward compatibility. These characteristics make it well suited for building robust data science applications that can handle complex data processing tasks and run reliably in production environments.
Scalability
Java’s scalability is another key advantage for data science projects. Java-based frameworks such as Apache Hadoop and Apache Spark are designed specifically for distributed computing, enabling parallel processing and distributed storage across multiple machines or nodes.
This scalability extends to performance optimization, allowing data-intensive applications to leverage techniques such as multi-threading and asynchronous programming for better resource utilization and faster insights.
Unique Syntax
Finally, Java’s syntax is designed to be straightforward and easy to understand. Its syntax follows a clear and structured format, making code more readable and reducing the likelihood of errors. This is especially important in data science, where complex algorithms and data processing tasks are involved.
Java’s syntax provides a good balance between readability, simplicity, and performance, making it a good choice for data science tasks. Its object-oriented nature, strong typing, and interoperability help build robust and scalable data science applications.
[Read also: Best Java IDE in 2023: Top 6 Java Integrated Development Environments Chosen by Our Developers]

How to Get Started with Java for Data Science
As a Java developer venturing into data science, there are a few essential steps to take. First, focus on strengthening your Java programming skills by ensuring a solid understanding of Java’s syntax, data types, and object-oriented concepts. With this solid foundation, you can delve into the fundamentals of data science, covering areas such as data manipulation, statistics, machine learning algorithms, and data visualization.
Once you’re armed with this knowledge, you can explore Java libraries designed specifically for data science, such as Apache Hadoop, Apache Spark, Weka, and Deeplearning4j, which we’ll explore in more detail in the next section. Initially, you can practice using these libraries with small datasets to hone your data analysis and visualization skills.
As you learn, remember to engage with the data science community. You can participate in online forums and collaborate on open-source projects to learn from experienced data scientists. Keep up with the latest developments by following industry blogs and exploring online courses.
By combining your Java programming skills with a solid understanding of data science, you are sure to succeed as a Java developer specializing in the challenging world of data science.
8 Java tools and frameworks for data science you need to know
In the previous sections, we’ve mentioned that one of the key advantages of Java is its rich ecosystem. Let’s look at eight of the most popular and important toolkits, frameworks, and libraries that are essential for performing data-related tasks in Java:

Apache Hadoop
When talking about Java’s role in data science, the first thing to mention is Apache Hadoop – a widely used open source framework that facilitates the processing and analysis of large and complex data sets. Hadoop’s core components, such as the Hadoop Distributed File System (HDFS) and MapReduce, enable efficient storage and parallel processing of large data sets across clusters of commodity hardware.
Data scientists can leverage Hadoop’s distributed nature to handle massive data volumes and achieve fault tolerance, ensuring reliable data processing even in the presence of hardware failures. In addition, the Hadoop ecosystem provides a variety of tools and libraries, such as Hive and Pig, that facilitate data manipulation and analysis. Java’s compatibility with Hadoop enables data scientists to write custom MapReduce programs to perform complex data transformations and advanced analytics.
Apache Spark
Spark is a fast, general-purpose, open source cluster computing framework designed to process and analyze large data sets quickly and efficiently.
It provides a distributed computing environment that enables parallel processing across a cluster of machines, resulting in faster data processing. Spark provides in-memory data storage, enabling fast access to data sets and reducing disk I/O operations. Its core abstraction, known as Resilient Distributed Datasets (RDDs), enables fault tolerance and data parallelism.
Spark supports multiple programming languages, including Java, making it accessible to a wide range of developers and data scientists. It provides high-level APIs for batch processing, interactive querying (via Spark SQL), stream processing (via Spark Streaming), and machine learning (via Spark MLlib).
Kafka
Kafka is another powerful tool that greatly improves data handling and streaming architectures, especially in the context of data science. Apache Kafka is an open-source distributed event streaming platform for processing real-time data feeds. It scales horizontally to handle high-throughput, real-time data streams across multiple machines or clusters. Its fault-tolerant design provides data replication and durability, ensuring data security and availability even in the face of failures. Kafka excels at stream processing and real-time analytics, allowing data to be processed and analyzed as it arrives.
With Kafka, data scientists can overcome the challenges of integrating data, handling real-time data, and ensuring data reliability to unlock the full potential of streaming data in their data science workflows.
Apache Mahout
Apache Mahout is a powerful linear algebra framework that provides data scientists with scalable machine learning algorithms and advanced analytics capabilities. Designed specifically for data science tasks, Mahout facilitates the implementation of various machine learning techniques in a Java environment. Its key features include a rich set of scalable algorithms that can efficiently handle large datasets. Mahout provides algorithms for collaborative filtering, clustering, classification, and recommendation systems, among others. It leverages distributed computing frameworks such as Apache Hadoop and Apache Spark to process data in parallel, making it ideal for big data analytics.
Its flexibility and extensibility allow data scientists to customize algorithms or develop new ones tailored to their specific needs. With Mahout, an experienced data scientist can harness the power of machine learning algorithms and tackle complex data science challenges, making it a valuable tool in the Java software development environment, especially in the context of data science.
Deeplearning4j
Eclipse Deeplearning4j, or DL4J for short, is a powerful open-source Java library specialized, as the name suggests, for deep learning. It provides a comprehensive set of tools and functionalities for building and training deep neural networks. Deeplearning4j is designed to be scalable and efficient, allowing data scientists to work with large datasets and leverage the power of other Java distributed computing frameworks such as Apache Hadoop and Apache Spark.
Deeplearning4j provides a wide range of deep learning algorithms and models, including convolutional neural networks (CNNs), recurrent neural networks (RNNs), and deep belief networks (DBNs). These algorithms are effective in solving complex tasks such as image and speech recognition, natural language processing, anomaly detection, and more.
The library also provides support for distributed training, allowing efficient use of computing resources across multiple machines or clusters. In addition, Deeplearning4j offers an easy-to-use and intuitive interface, along with comprehensive documentation and tutorials, making it accessible to both novice and experienced data scientists. It integrates with popular Java tools and frameworks such as Apache Kafka, Apache Hadoop, and Apache Spark, further enhancing its versatility and usability in real-world data science projects.
Weka
Weka, developed at the University of Waikato, New Zealand, is another popular and powerful open-source toolkit focused solely on machine learning that is worth mentioning. It contains a rich collection of visualization tools and algorithms for data analysis and predictive modeling, along with graphical user interfaces for easy access to these functions.
Weka includes many machine learning algorithms, including decision trees, random forests, support vector machines, k-nearest neighbors, and neural networks, among others. These algorithms can be easily applied to data sets to build predictive models or extract patterns and insights.
Another noteworthy feature of Weka is its extensive support for experiment and model evaluation. It provides various evaluation metrics and statistical tests to assess the performance and significance of machine learning models. Users can perform cross-validation, training/test set evaluation, and experiments to compare and fine-tune different algorithms.

ADAMS
In the context of data science, ADAMS (Advanced Data Mining and Machine Learning System) is a flexible and comprehensive open source framework that facilitates the development and deployment of data science workflows. ADAMS aims to streamline the end-to-end data science process by providing a visual interface for creating, executing, and managing complex data mining and machine learning workflows.
ADAMS provides a modular and extensible architecture that allows users to build custom workflows by combining pre-existing components known as actors.
A key feature of ADAMS is its focus on automation and reproducibility. Workflows built in ADAMS can be easily saved, versioned, and shared, ensuring transparency and reproducibility of data science experiments. This feature is especially useful when collaborating with team members or working on large-scale projects.
ELKI
Last but not least, let’s briefly mention the Environment for Developing KDD Applications Supported by Index-Structures, or ELKI for short. It is an open-source Java framework designed for data mining and knowledge discovery tasks. ELKI provides a wide range of algorithms and data structures that enable efficient processing, analysis, and visualization of large data sets.
ELKI focuses on advanced data mining techniques, including clustering, outlier detection, and similarity search. It provides a comprehensive set of algorithms for these tasks, allowing data scientists to apply state-of-the-art techniques to their datasets.
One of ELKI’s key strengths is its emphasis on index structures. Index structures are data structures optimized for fast retrieval and search operations. ELKI provides a wide range of index structures, such as R-trees, KD-trees, and cover trees, which enable efficient spatial and similarity-based queries on large datasets.
In addition, ELKI provides a flexible and extensible framework that allows users to develop custom algorithms and integrate external libraries. It also provides visualization tools to facilitate understanding and interpretation of data mining results.
[Read also: Guide to Java Profilers: Which Performance Monitoring Tool Is the Best?]

Java vs Python for Data Science
Python and Java are two popular programming languages that have gained significant traction in the field of data science. While both languages offer capabilities for data science tasks, they have distinct characteristics that make them suitable for different aspects of the data science workflow.
Python is widely recognized as the language of choice for data science because of its simplicity, readability, and extensive library ecosystem. It provides several powerful libraries designed specifically for data science, such as NumPy, Pandas, and Scikit-learn. These libraries provide extensive functionality for data manipulation, numerical computation, machine learning, and statistical analysis. In addition, Python’s popularity within the data science community means that there are plenty of resources, tutorials, and community support available.
Java, on the other hand, excels in areas that require scalability, performance, low latency numbers, and enterprise-grade systems. It is well suited for handling large amounts of data and building robust, distributed applications. Java’s strength lies in its ability to integrate with existing enterprise systems and work seamlessly with large-scale data processing frameworks such as Apache Hadoop and Apache Spark. Java also provides libraries and frameworks for machine learning and data analysis, such as Weka, Deeplearning4j, and ELKI. These libraries provide powerful algorithms and tools for data mining, machine learning, and visualization. Java’s static typing and strong typing discipline provide a level of code security and maintainability that can be advantageous for large-scale projects. In terms of performance, Java has a reputation for efficient execution and is often preferred in scenarios where speed is critical, such as real-time data processing.
Even though it may be surprising for some, Java actually comes on top when it comes to performance in comparison to Python in some scenarios. According to a recent research paper focused on measuring the energy efficiency of programming languages, researchers performed a multitude of benchmarks and tests. According to their results, compiled languages “tend to be” the most energy-efficient and fastest-running, but Java wasn’t far behind beating other interpreted languages like Python by quite a substantial margin.
Real-world examples of the use of Java for data science projects
Java is undoubtedly a solid programming language for data-related programming projects, and many top companies in various industries have recognized this. Organizations such as Airbnb, Spotify, Uber, continue to use Java to host mission-critical data science applications.
So in what business scenarios is Java a good fit for data science projects?
Prime examples are recommendation engines that power personalization systems in e-commerce, streaming platforms, and social media channels. Why these services? All of these digital products need to process incredibly large amounts of data in real-time. Java’s scalability and compatibility with distributed computing frameworks make it well suited for processing and analyzing large data sets and for building enterprise-class systems where high-performance software is a top priority.
Conclusion
In summary, Java emerges as a compelling choice for data scientists due to its unique combination of key features and powerful frameworks. Its simplicity, readability, and extensive library ecosystem make it accessible and efficient for tackling data science tasks.
The language’s scalability allows it to handle large amounts of data and optimize performance, while its enterprise-level integration capabilities ensure seamless connectivity with existing systems. In addition, Java’s compatibility with distributed computing frameworks enables data scientists to tackle complicated large-scale data processing and machine learning tasks with ease.
Related Posts
Thank you for taking the time to read our blog post!
{kind=link}
{kind=link}