
What Are Large Language Models: Definition + Best Examples
The field of artificial intelligence machine learning has made unprecedented progress in recent years. But one question remains – will the machines be albe understand and communicate using human language? Well, there’s an exciting new development on the horizon.
Enter large language models – cutting-edge AI tools that are opening up new horizons for communication, problem solving, and information processing.
In this article, we delve into the world of large language models, unraveling their inner workings and exploring the key examples that have changed the landscape of natural language processing. You won’t want to miss this, as LLMs are at the forefront of the ongoing AI transformation!
What are Large Language Models – definition
Large Language Models (LLMs) are sophisticated artificial intelligence systems designed to understand and generate human language. These systems are designed to learn the patterns, structures, and relationships within a given human language and use them for various narrow AI tasks such as text translation and text generation. This allows them to generate new content, such as essays or articles, that are similar in style to a particular author or genre.
Large language models are based on neural network architectures that contain a huge number of parameters that allow them to process and interpret large amounts of text data. The quality of a language model varies greatly, depending mainly on its size, the amount of data it was trained on, and the complexity of the learning algorithms used during training.
So how do large language models work? In short, it is a two-step process.
First, they undergo pre-training, where they learn linguistic patterns, grammar, and contextual relationships from a variety of text sources. This phase gives them a basic understanding of the language.
Next, the models are fine-tuned to specific tasks using narrower datasets, refining their performance in tasks such as translation, summarization, and question answering. LLMs have gained attention for their ability to produce coherent and contextually relevant text, making them valuable in various applications across industries.

From Transformer Model to Large Language Model – How do LLMs work?
As humans, we perceive written text as a collection of words. Sentences are essentially sequences of words from which we can derive meaning. Documents, on the other hand, are larger sequences of sentences that make up entire chapters, sections, and paragraphs.
Computers, on the other hand, see text as just a string of characters. Search engines like Google perceive what you type into the search box as a collection of keywords to match results, not the deeper meaning behind it.
So how do we teach computers to understand written text the way we do?
In the year 2017, Ashish Vaswani and other researchers released a research paper titled “Attention is All You Need,” which introduced the transformer model – a novice approach to building neural networks constructed around the concept of attention mechanisms.
Unlike traditional recurrent neural networks, the attention mechanism allows the model to process entire sentences or even paragraphs at a glance, rather than analyzing individual words sequentially. This capability greatly improves the Transformer model’s contextual understanding of written words. Since its inception, numerous state-of-the-art natural language processing models have adopted the transformer architecture as their foundation.
[Read also: Future of Business Intelligence: Emerging Trends]

To process textual input using a transformational model, the text is first broken down into a sequence of words called tokens.
These tokens are then translated into numerical values and transformed into embeddings, which are vector-based representations that preserve the semantic meaning of the tokens. The encoder component of the transformer then processes the embeddings of all the tokens to generate a context vector. Let’s look at this example text from Wikipedia:
Ceres is a dwarf planet in the asteroid belt between the orbits of Mars and Jupiter.
It was the first asteroid discovered, on 1 January 1801, by Giuseppe Piazzi at Palermo Astronomical Observatory in Sicily
and announced as a new planet. Ceres was later classified as an asteroid and then a dwarf planet – the only one always inside Neptune's orbit.A tokenized version of this paragraph would look like this:
['Ceres', 'is', 'a', 'dwarf', 'planet', 'in', 'the', 'asteroid', 'belt', 'between', 'the', 'orbits', 'of', 'Mars', 'and', Jupiter', '.',
'It', 'was', 'the', 'first', 'asteroid', 'discovered', ',', 'on', '1', 'January', '1801', ',', 'by', 'Giuseppe',
'Piazzi', 'at', 'Palermo', 'Astronomical', 'Observatory', 'in', 'Sicily', 'and', 'announced', 'as', 'a', 'new', 'planet', '.',
'Ceres' 'was' 'later' 'classified' 'as' 'an' 'asteroid' 'and' 'then' 'a' 'dwarf' 'planet' '–' 'the' 'only' 'one' 'always' 'inside' 'Neptune' ''' 's' 'orbit' '.']Here is the embedded version of the above text:
[ 2.48 0.22 -0.36 -1.55 0.22 -2.45 2.66 -1.6 -0.14 2.26
-1.26 0.21 -0.61 -1.79 1.87 -0.16 3.34 -2.67 0.42 -1.31
...
2.91 -0.77 -0.13 -0.14 -0.63 -0.26 -2.47 -1.22 -1.37 1.63
1.13 0.03 -0.58 0.8 1.88 1.05 -0.82 0.09 0.48 0.73]The context vector embodies the core meaning of the entire input. Using this vector, the transformer’s decoder generates responses guided by contextual cues, rather than using a simple linear keyword approach.
This technique is called autoregressive generation, and it is at the core of the operating mechanism of large language models in the form of a transformer model designed to handle very long input texts. The context vector has a considerable capacity, which enables the AI model to handle complex concepts. In addition, both the encoder and decoder are composed of numerous layers to enhance their processing capabilities.
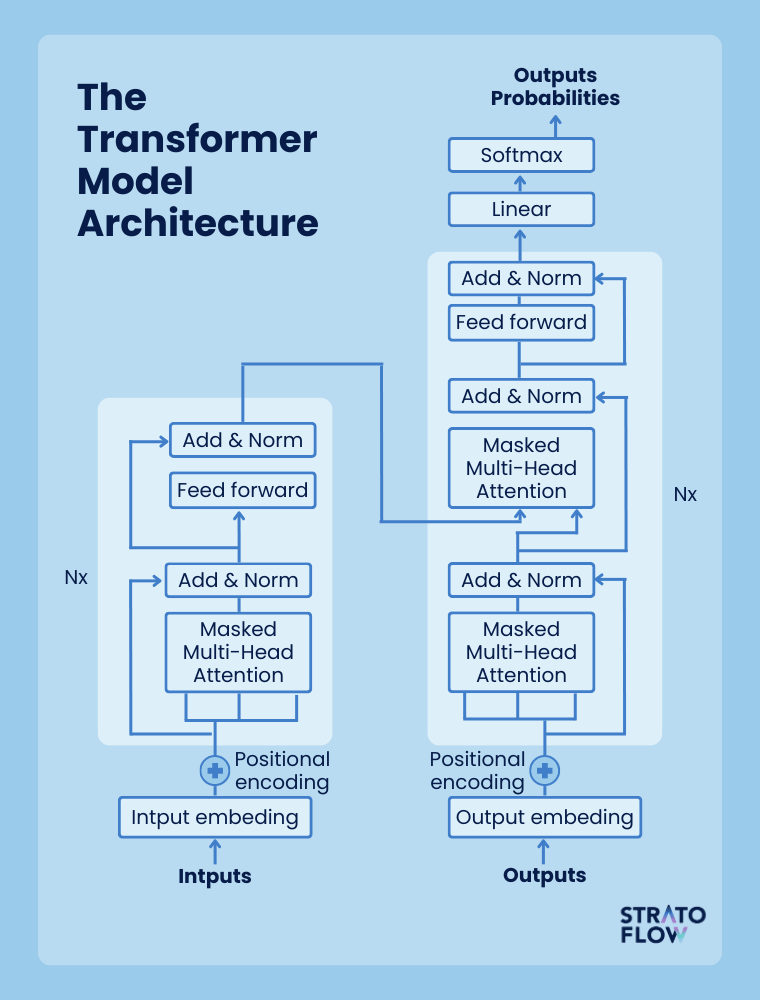
Transformer models laid the foundation for subsequent advances. The advent of LLMs, exemplified by models such as GPT-3, marked a significant leap forward.
These models, based on Transformers, increased in scale by incorporating billions of parameters. This expansion enabled them to ingest and understand large amounts of textual data. The pre-training and fine-tuning process honed the capabilities of LLMs, enabling them to understand and generate human-like text in a variety of tasks.
GPT-3 and GPT-4 language AI models, both underwent a lengthy training process on large amounts of training data, textual information obtained from the Internet. Training can take anywhere from weeks to months, depending on the size of the training data.
What is a good sample of written text for the LLMs training process?
Well, if we want LLM to provide us with helpful information on any topic, the training data should be as broad and extensive as possible. It should include a wide variety of materials such as books, articles, websites, and different content sources. Teams responsible for AI development have to remember that during the training phase, the large language model acquires an understanding of the statistical correlations between words, phrases, and sentences. As a result, it gains the ability to generate coherent and contextually appropriate responses when presented with a prompt or query.
Of course, artificial general intelligence hasn’t yet been achieved by large language models. They can only generate content based on their training data, but that may soon change. According to recent reports, the latest iteration of OpenAI LLM – GPT-5 – may be on the verge of achieving Artificial General Intelligence (AGI) and becoming nearly indistinguishable from a human in its ability to generate natural language responses.
If true, this breakthrough in AI could have significant consequences. The prospect of achieving AGI with the release of GPT-5 for ChatGPT is both exciting and unsettling, as we are unable to fully comprehend the implications of such an achievement.
[Read also: Launch Your Business to the Cloud: Enterprise Cloud Definition, Business Benefits and Key Solutions]
Why are Large Language Models important?
Unless you’ve been living under a rock for the past 6 months, integrations of LLMs and ChatGPT have been popping up in a plethora of applications and services. While some of these integrations may be more questionable than others, one thing is for sure – LLMs offer immense opportunities for various industries, and many of them are still untapped.
Let’s take a quick look at the key benefits of artificial intelligence language models for modern businesses:

Natural language understanding and generation
First and foremost, large language models have the ability to perform natural language processing to understand and generate human language at an impressive level. This capability is critical for tasks such as language translation, content creation, chatbots, and virtual assistants, improving communication between humans and machines.
Efficiency in information retrieval
LLMs can quickly sift through vast amounts of textual data and extract relevant information. This efficiency is invaluable for tasks such as research, data analysis, and extracting insights from unstructured text sources.
Automation of routine tasks
Large language models enable the automation of repetitive and time-consuming tasks, such as composing emails, generating simple code, and summarizing long documents. Of course, these tasks still require human input and oversight, but the time required to complete them is greatly reduced. This in turn increases productivity and frees up human resources for more creative and complex activities.
Multilingual communication
LLMs can facilitate seamless communication across multiple languages by offering translation services. This is particularly valuable in global business operations, diplomacy, and bridging language barriers in various contexts.
Creative content generation
AI language models can also help marketing teams with creative content creation, including writing articles and poems, and even assisting with script writing. Of course, no serious marketer should let GPT write all their copy on autopilot, but these tools can certainly inspire creativity and help content creators brainstorm ideas.
Customer support and engagement
LLM’s ability to generate text is also being used by retailers to serve as intelligent customer support agents, answering common questions and providing assistance around the clock. This improves customer satisfaction and reduces response times.
[Read also: Java Is Not Dead Yet! Why Is Java So Popular Even In 2023?]
Large Language Models examples
By now we know how LLMs work and what value they bring to companies from various sectors. Let’s now see what are the main players in the LLM market.
Here are seven examples of the most prominent large language models:
GPT

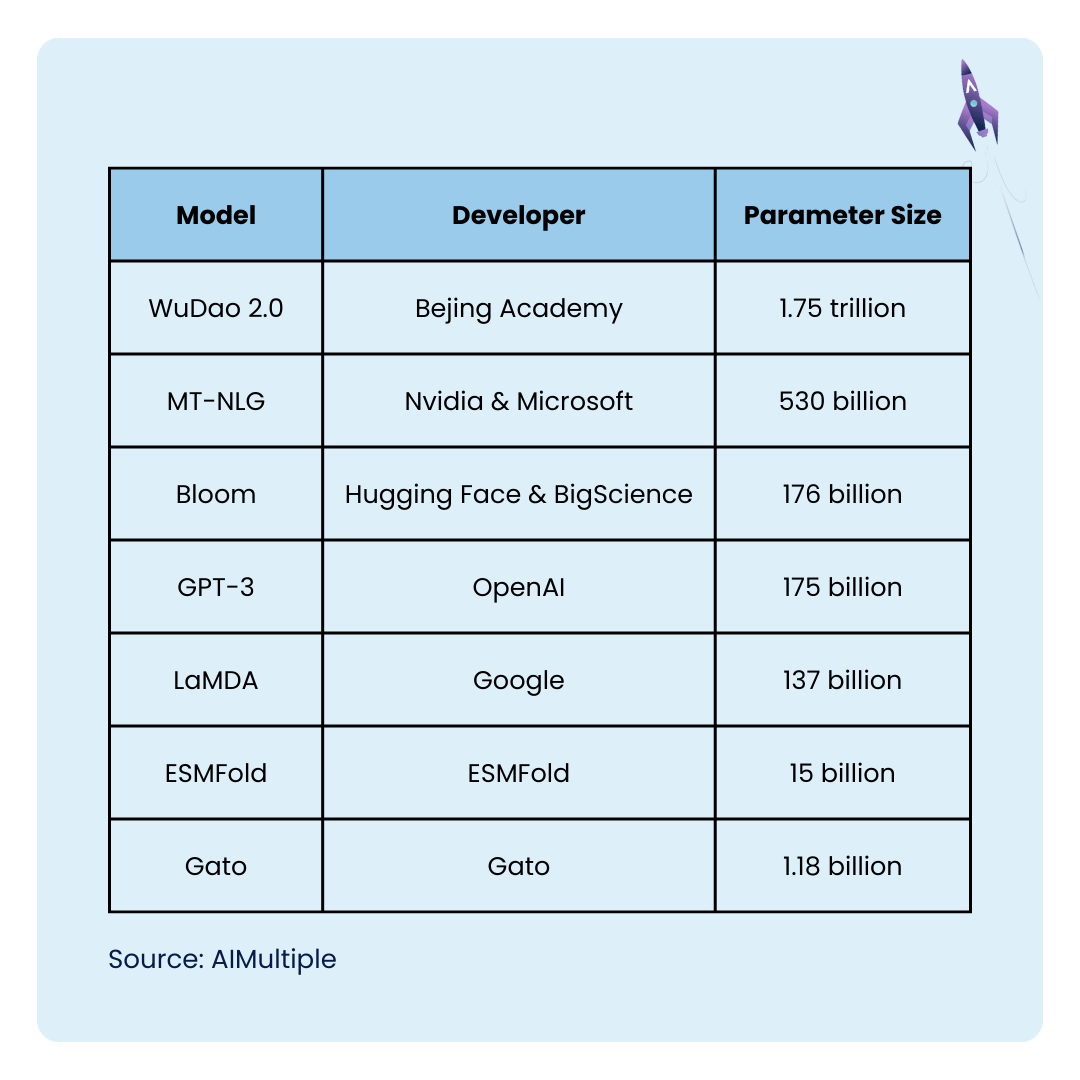
Generative Pre-trained Transformers, commonly known as GPT, is a family of large language models that use the transformer architecture to power generative AI applications. GPT-3 is one of these models with over 175 billion parameters. It was released in 2020. GPT-3 uses a decoder-only transformer architecture and is up to 10 times larger than its predecessor. GPT-3’s training data includes Common Crawl, WebText2, Books1, Books2, and Wikipedia.
After 3 came GPT-3.5 – an improved version of GPT-3 with fewer parameters. GPT-3.5 was fine-tuned using reinforcement learning from human feedback. GPT-3.5 is the version of GPT that currently powers the free version of ChatGPT.
In 2023, OpenAI released GPT-4 – their largest model AI system to date. Like the others, it’s a transformer-based model, but unlike its predecessor, its parameter set has not been released to the public. There are rumors that the model has more than 170 trillion parameters – an absolutely incredible number compared to the competition.
OpenAI treats GPT-4 as a multimodal model – it can not only generate text, but also process, understand, and generate images. The latest generation of the GPT model also introduced a system message that allows users to specify the tone of voice and task. GPT4 is currently the model released to the public as the premium version of ChatGPT.
BERT

BERT, or Bidirectional Encoder Representations from Transformers, is a family of LLMs that Google introduced in 2018.
Like GPT, BERT is a transformer-based model that can read, process, and convert data sequences. BERT’s architecture is a stack of transformer encoders with over 340 million parameters. It was pre-trained on a large corpus of data, which was further fine-tuned to perform specific tasks along with natural language processing.
LaMDA

LaMDA (Language Model for Dialogue Applications) is a family of large language models developed by Google Brain and announced in 2021.
Unlike BERT and GPT, LaMDA is a decoder-only transformational model and was pre-trained on a large number of text files. In 2022, LaMDA received some media attention when a former Google engineer went public with claims that the program was sentient, but as of 2023 his claims remain unproven. LaMDA was built using the Seq2Seq architecture.
Falcon 40B
Falcon 40B is a transformer-based, causal decoder-only model developed by the Technology Innovation Institute.
It is an open source LLM and has been trained on English written text only. Two main versions are available: Falcon 1B and Falcon 7B with different numbers of parameters (1 and 7 billion, respectively).
PaLM
PaLM (The Pathways Language Model) is another transformer-based model with 540 billion parameters developed by Google. It currently powers their AI chatbot Bard – one of the main competitors to the popular ChatGPT.
It was trained using multiple TPU 4 Pods – Google’s custom hardware for machine learning. PaLM specializes in reasoning tasks such as coding, math, classification, and question answering, but it also excels at breaking down complex tasks into simpler subtasks.
Llama
Llama (Large Language Model Meta AI) is Meta’s own large language model that was released in 2023.
Its largest version is 65 billion parameters in size, making it one of the largest language models on the market. Llama was originally released to approved developers and researchers, but is now released under the open-source license. The main selling point of Llama is that it is smaller in size and requires less computing power to use.
WuDao 2.0
Developed by Beijing Academy of Artificial Intelligence, Wu Dao 2.0 is an intelligent multi-modal AI model, which means that it is not only a large language model, but also an advanced tool that can generate images, and has self-improving capabilities.
Wu Dao was trained with FastMoE, an open-source Mixture of Experts (MoE) system on 4.9 terabytes of high-quality images and texts in both English and Chinese.
[Read also: AI Insurance: The Impact of AI on The Insurance Industry In 2024]
Conclusion
In recent months, the world of artificial intelligence has blossomed with new advances such as stable diffusion, advanced personalization, generative AI, and large language models.
As we continue to explore the potential of Large Language Models, it is clear that they are not just tools, but game-changers that will reshape industries, improve accessibility, and propel us into an era where seamless human-machine interaction is no longer a distant aspiration, but a tangible reality.
Related Posts
Thank you for taking the time to read our blog post!
{kind=link}
{kind=link}