
How to Build a Search Engine: Step by Step Guide
Although we may not pay much attention to them, search engines have become a crucial aspect of our daily lives.
They serve us in various places, from old and well-known Google to sophisticated travel metasearch engines and e-commerce sites.
In today’s guide, we will take a closer look at the inner workings of these systems and see what it takes to build your own custom search engine.
What is a search engine?
A search engine is a software application designed to help users find information on the Internet.
It uses algorithms to search the Internet based on keywords or phrases provided by the user and returns a list of results, typically in the form of web pages, that are most relevant to the user’s query. There are generally three key elements that go into any search engine:
- Search algorithms
- Data to analyze and generate results from
- A cloud-based infrastructure to support systems operations
While most developers focus on the search algorithms themselves, the supporting functionalities and architecture are just as important.
How do search engines work?
Before we can build a search engine, we first need to figure out how one works.
Here are five key components of modern search engines that allow them to sort through huge amounts of data and deliver relevant results to their users.
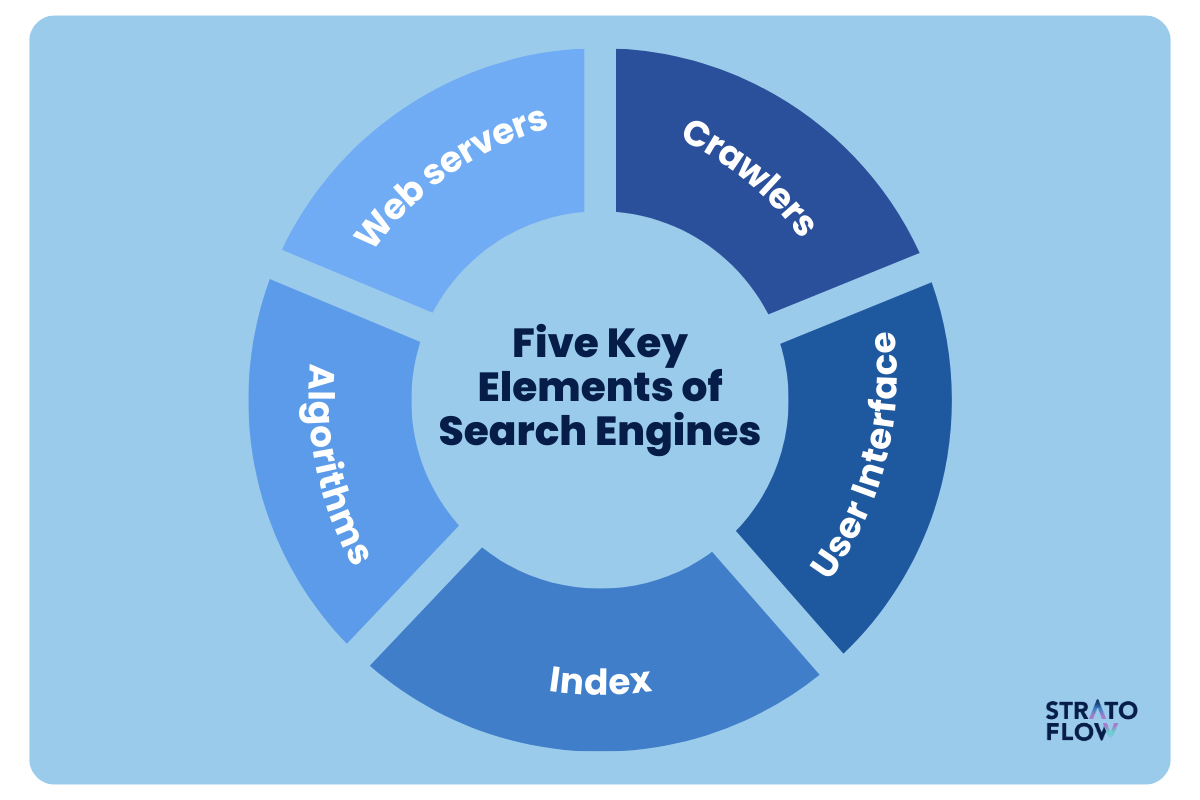
Part 1: Web servers
In the context of search engines, a web server plays a fundamental role by hosting and delivering web content to both users and search engine crawlers. When a user or a search engine crawler requests a page, the web server processes this request and sends back the necessary files, such as HTML, CSS, JavaScript, images, and other assets.
This means that the web server provides the raw content that is indexed and evaluated for relevance.
Web servers also manage the structure of URLs, ensuring that each unique page on a website can be accessed and indexed by search engines.
Part 2: Crawlers (Spiders)
Even the most basic search engine must gather the data it needs to generate results.
That’s the job of crawling – gathering data about websites and their pages, such as content, images, and links.
Web crawlers, or spiders, are automated software that navigate websites, analyze content, and follow links to discover new pages. This process helps build and update the search engine’s index with the most current and relevant data.
Part 3: Index
Once data is collected, it’s processed and organized in the index, a large database where crawlers store information like text, URLs, titles, images, and links.
The index optimizes data retrieval, allowing the search engine to quickly find relevant information for user queries.
Its organization is crucial for delivering accurate and efficient search results from the vast amount of web data.
Part 4: Page Rank algorithm
By now the search engine has collected, processed, and organized the key information about our content.
Now comes the time for the most important part – using all the data to generate meaningful results for each individual user.
Search algorithms are complex sets of rules and calculations used by search engines to determine the relevance and ranking of pages in their index in relation to a user’s query.
Different sites and engines will have different ranking algorithms. All of them take into account various factors, such as keyword density, site structure, link quality, and user experience, to evaluate and rank webpages. The goal is to provide the user with the most relevant and high-quality results for their search.
Part 5: User Interface (SERPs)
When our search results are ready, the system needs to present them to users in the most appealing and intuitive way.
The Search Engine Results Page, commonly referred to as the SERP, is the page that displays the results of a user’s search query.
The SERP typically lists relevant web pages along with snippets, images, and links to preview their content.
It may also include ads, rich results (like reviews and images), and specialized results (such as news, videos, or maps) to offer comprehensive information. Its design and functionality are crucial for user experience, as it helps users interact with the search engine and navigate to other pages.
Building your own search engine software – step-by-step process
So we know what elements go into search engines, now we can see how you can build one yourself.
Below we’ve created a five-step process to give you a basic understanding of how one might go about building their own search engine. If you need more professional help learn more about our custom search solutions.
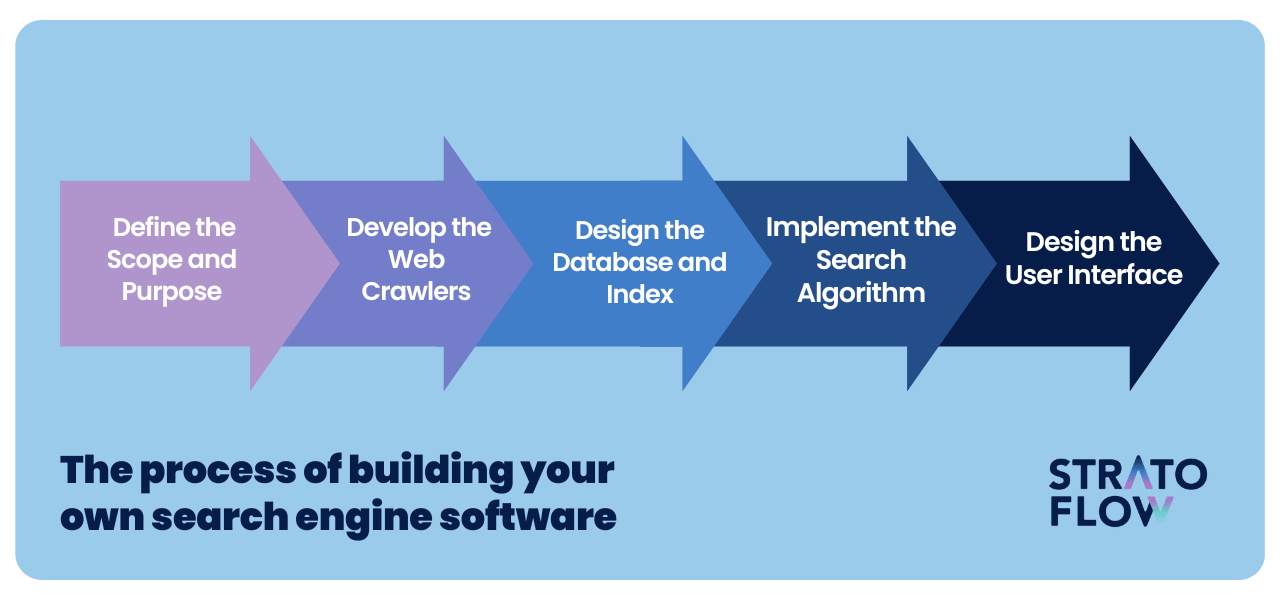
Step 1: Define the Scope and Purpose

Before diving into the technical aspects of building your own custom search engine, the very first and arguably most critical step is to define the scope and purpose of your search engine.
Understanding what you want to achieve with your search engine will guide every subsequent decision, from the technologies you choose to how you design your indexing and ranking algorithms.
Purpose of Your Search Engine
Start by clarifying the primary goal of your search engine.
What kind of information do you want to help users find?
Are you building a general-purpose search engine, or will it be highly specialized?
For instance, are you aiming for a search engine that specializes in academic papers, product searches, real estate listings, or niche content like recipes or music?
Scope: Narrow vs. Broad
The scope of your search engine will directly affect its complexity and the resources required to build and maintain it.
A broad search engine might crawl billions of websites, requiring significant computing resources for crawling, storage, and indexing. On the other hand, a narrowly focused search engine could target a specific domain or category, which may allow for more detailed customization, better relevancy, and lower computational requirements.
Consider whether your search engine will:
- Index the entire web or just a specific subset of websites (e.g., e-commerce search, academic databases).
- Focus on textual content, multimedia, or specialized data (e.g., structured metadata).
- Serve a general public audience or a more specific group of users (e.g., employees within a company or users of a specific app).
Step 2: Develop the Web Crawlers

After defining the scope and purpose of your custom search engine, the next step is to develop web crawlers.
Remember that these are essential components that navigate the web, discover content, and download it for indexing in your search engine.
Purpose of Web Crawlers
Using programming languages like Java and libraries and tools such as SpringBoot, Openkoda, Crawler4j, and Jsoup, you can create crawlers capable of collecting various types of data, including web page content, metadata, and links.
The four primary goals of a web crawler are:
- Discover content: Find new or updated web pages by following hyperlinks.
- Download content: Fetch the HTML, metadata, or other relevant assets for each page.
- Parse content: Extract meaningful information such as text, titles, headers, or structured data.
- Respect policies: Follow web standards like the
robots.txtfile, which dictates which parts of a website should be crawled or ignored.
Make sure that the web crawler you are designing checks out all of these four boxes.
Building Web Crawlers Using a Java-Based Tech Stack
While you can build a web crawler from scratch, it’s often more efficient to use a library that handles the lower-level details like making HTTP requests and parsing HTML. Two commonly used libraries are:
- Jsoup: A powerful HTML parser for Java that allows you to extract and manipulate data from web pages.
- Apache HttpClient: For more complex HTTP operations, like handling sessions or cookies, this library can handle HTTP communication.
Here’s how you can create a simple crawler in Java using Jsoup to fetch and parse web pages.
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
public class WebCrawler {
public static void main(String[] args) {
String url = "https://example.com";
crawl(url);
}
public static void crawl(String url) {
try {
// Fetch the HTML content of the page
Document document = Jsoup.connect(url).get();
// Extract the title of the page
String title = document.title();
System.out.println("Title: " + title);
// Extract all hyperlinks on the page
document.select("a[href]").forEach(link -> {
System.out.println("Link: " + link.attr("abs:href"));
});
} catch (Exception e) {
System.err.println("Error fetching the page: " + e.getMessage());
}
}
}
To build a functional crawler, you’ll need to handle the recursive nature of crawling, where the crawler follows links found on each page.
Depth control is key.
Without it, a crawler might follow an endless chain of links, potentially causing performance issues or even crashing due to memory overload.
You should implement a mechanism that limits how many “hops” away from the initial URL the crawler can go.
Respecting robots.txt
Every responsible web crawler must adhere to the robots.txt file that websites use to manage crawler access. The robots.txt file is located at the root of a website (e.g., https://example.com/robots.txt) and specifies which parts of the site are off-limits to crawlers.
To implement this responsibly:
- Fetch the
robots.txtfile before crawling a domain. - Parse the file to understand which URLs should be disallowed.
- Integrate the rules into your crawling logic so that the crawler avoids restricted sections.
Step 3: Design the Database and Index

After developing your web crawler, the next critical step in building a custom search engine is designing the database and index.
This part is essential for organizing the data that your crawler collects, making it accessible for fast search and retrieval.
NoSQL databases, such as MongoDB or Elasticsearch, are more flexible and scalable for handling large volumes of unstructured or semi-structured data. Elasticsearch, in particular, is a popular choice for search engines because it provides native support for indexing and searching large volumes of text.
When designing your database schema, focus on what kind of data you’ll need to store:
- URLs: The address of the web page.
- HTML Content: The raw HTML or the text extracted from it.
- Metadata: Information such as the title, meta tags, and publication date.
- Link Structure: Internal and external links on each page.
- Crawl Status: Track if a page has been crawled, updated, or needs to be re-crawled.
Build the Indexing System
Once your data is stored in the database, the next step is to design the index. The index allows for rapid retrieval of documents in response to search queries by mapping terms to the documents in which they appear.
- Tokenization: it is the process of breaking down the text of a document into individual words or tokens. These tokens are the core of your index. For example, the sentence “Openkoda speeds up software development” would be tokenized into “Openkoda,” “speeds,” “up,” “software,” and “development.” Each token is stored in the index, mapping it to the documents where it appears.
- Inverted Index: It is the most common data structure used in search engines. This is a mapping from words (tokens) to the list of documents in which they appear. For example:
"custom" → [doc1, doc2, doc5]
"search" → [doc2, doc4]- Stemming and Lemmatization: To improve search accuracy, you’ll want to normalize words so that different forms of the same word (like “run,” “running,” “ran”) are treated as the same token.
- Document Ranking and Weighting: After locating the relevant documents for a given query, the next step is to rank them based on relevance. Common techniques include TF-IDF (Term Frequency-Inverse Document Frequency), which ranks documents based on the importance of a word in a particular document relative to how frequently it appears across the dataset.
Implementing Indexing Using Java and Libraries
If you’re building the indexing system using Java, several open-source libraries can help you create efficient search and indexing capabilities without building everything from scratch.
Two of the most popular options include Apache Lucene and Elasticsearch.
We recommend the latter because it offers a higher-level, easy-to-use interface and out-of-the-box features such as distributed search, real-time indexing, and scalability.
Set up an Elasticsearch index to store documents, and define the structure (e.g., URL, title, content).
Use the Java client to index documents by converting them into JSON format and sending them to Elasticsearch.
For searching, you can query the index using Elasticsearch’s REST API or the Java client, retrieving relevant documents based on search terms. Elasticsearch handles the complexities of scaling, distributed indexing, and near real-time search, making it efficient for large datasets.
Step 4: Implement the Search Algorithm

Once you have built your web crawlers and established a well-structured index, the next crucial step is to implement the search algorithm.
This is where your search engine transforms user queries into actionable results by retrieving and ranking the most relevant documents from the index.
Elasticsearch for Querying and Ranking
If you’re using Elasticsearch for indexing, you can leverage its built-in query and ranking capabilities to streamline your search algorithm development.
Elasticsearch supports a variety of query types (e.g., match, term, range queries), which allow you to control how documents are retrieved and ranked.
Here’s how you can implement a basic search query in Elasticsearch using Java:
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.search.builder.SearchSourceBuilder;
public class SearchEngine {
public void searchDocuments(String indexName, String queryTerm) throws Exception {
SearchRequest searchRequest = new SearchRequest(indexName);
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
// Match query to search for documents containing the query term
searchSourceBuilder.query(QueryBuilders.matchQuery("content", queryTerm));
searchRequest.source(searchSourceBuilder);
SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);
searchResponse.getHits().forEach(hit -> System.out.println(hit.getSourceAsString()));
}
}This is a basic match query, but Elasticsearch allows for more complex queries, such as multi-field queries, fuzzy searches (handling typos), and boosting specific fields to weigh them more heavily in search results.
Search Filters and Faceting
To improve user experience, you can implement filters and faceting to allow users to narrow down results.
For instance, if your search engine indexes products, you can add filters like price ranges, categories, or brands. Facets can be used to display aggregate data, such as how many documents belong to a particular category.
Elasticsearch makes it easy to add filters to your queries.
searchSourceBuilder.query(
QueryBuilders.boolQuery()
.must(QueryBuilders.matchQuery("content", queryTerm))
.filter(QueryBuilders.rangeQuery("price").from(10).to(100))
);
Insightful Recommendations for Search Algorithms
The search algorithm is by far the most challenging part of building a custom search engine. Here are a few tips for you from our experience working on similar systems:
- Start Simple, Then Optimize: Begin with basic matching algorithms and simple relevance models like TF-IDF or BM25. As you gather user feedback and test performance, you can refine and optimize with more advanced models.
- Use Existing Libraries: Leverage Elasticsearch’s powerful search and ranking capabilities instead of building complex algorithms from scratch. It allows you to quickly iterate and improve search relevance.
- Consider Performance: Make sure your algorithm can handle growing datasets efficiently. Elasticsearch’s distributed nature makes it easier to scale, but you should still monitor performance as data grows.
Step 5: Design the User Interface
At last, we come to the user interface design – an integral part of providing an intuitive and user-friendly experience.
This step involves creating a design that is not only visually appealing, but also easy to use, considering aspects such as how search results are displayed and how users enter queries.
Here are some best practices for you to follow:
Keep the Design Simple and Clean
When designing a search engine UI, simplicity is key. A clean, uncluttered layout focuses user attention on the search functionality without unnecessary distractions.
- Minimalistic layout: Avoid overwhelming users with too many options or visual elements. Stick to the essentials—a search bar, search button, and a list of results.
- Whitespace: Use whitespace effectively to create a visually appealing and easy-to-read layout. This helps users focus on the search bar and results without feeling crowded.
- Consistency: Maintain consistent font styles, sizes, and colors across the interface. This gives your search engine a professional, cohesive look.
Design a Prominent and Intuitive Search Bar
The search bar is the most critical element of your search engine’s UI. It should be easy to find, use, and understand.
- Central placement: Position the search bar at the center or top of the page where users expect it to be. It should be the focal point of the UI.
- Responsive design: Make sure the search bar scales well on all devices, from desktop to mobile. It should be easy to tap or click on any screen size.
- Placeholder text: Add helpful placeholder text within the search bar to give users an idea of what they can search for (e.g., “Search for products, articles, or pages…”).
Display Search Results in a Clear and Organized Way
When presenting search results, clarity and organization are key.
Each result should display vital information like the title, URL, and a brief snippet from the document or webpage.
These snippets allow users to quickly assess whether a result is relevant to their query. Highlighting the query keywords within the snippet adds an extra layer of context, making it clear why the result appeared.
If your search engine retrieves numerous results, consider using either pagination or infinite scroll to present them in manageable batches.
Implement Filtering and Facets
You should also look into integrating filtering and faceting into your search engine’s UI.
Filters enable users to narrow their results based on specific attributes like category, price, or date, providing more precise control over the search.
Faceting allows you to dynamically present relevant categories or data points based on the user’s query.
These features can be displayed as dropdowns or in a sidebar for easy access, using familiar elements like checkboxes or sliders to adjust values.
How much does it cost to build a custom search engine?
The cost of building a custom search engine can vary widely based on the scope, features, and scale of the project. Some factors that can influence the cost of building custom software like a search engine include:
- Scope of the project
- Complexity of the search algorithm
- Data volume and scalability requirements
- Number of features (e.g., filters, facets, auto-suggestions)
- Choice of technologies and tools (e.g., Elasticsearch, databases)
- Integration with external systems or APIs
- UI/UX design complexity
But let’s face it: search engines are immensely complex pieces of software.
The cost of building a custom search engine can vary significantly depending on several factors, but a rough estimate ranges between $50,000 to $500,000 or more.
At the lower end of the spectrum, if you are building a relatively simple search engine with basic features—such as keyword-based search, a limited dataset, and a straightforward UI—you could expect costs to start around $50,000 to $100,000.
However, as the complexity increases, so do the costs.
Advanced features like real-time indexing, personalization, sophisticated ranking algorithms, and handling large-scale data sets require more resources, which can drive the cost upward.
Specialized search engines
Let’s also take a moment to talk about specialized search engines since Google is not the only way of leveraging this technology in business.
Sometimes users demand more detail than the SERPs of popular major search engines can provide.
That’s where specialized search engines come in.
Specialized search engines are platforms designed to provide search results from a specific segment or type of content, focusing on a particular topic, industry, or type of data, such as academic papers, legal documents, or medical resources. Unlike general search engines, they prioritize and index content related to the specialized domain, providing users with more targeted, relevant, and in-depth results related to their specific queries within that domain.
Here’s a collection of some of the examples of popular specialized search engines .
Flights and Travel
- SkyScanner.net – The leading flights search engine, providing information about all carriers to help you find the best option.
- Kayak – Travel meta search engine that compares prices from multiple travel sites for flights, hotels, and car rentals.
- Booking.com – Is a hotel metasearch engine focused on hotel reservations but also offers deals on flights, car rentals, and vacation packages.
- Trivago – Metasearch engine that compares hotel prices from various booking sites.
Finance
- Yahoo! Finance – Provides financial news, data, and commentary including stock quotes, press releases, and financial reports.
- Investing.com – Offers tools for tracking stocks, commodities, currencies, bonds, and other financial assets, along with news and analysis.
Education and research
- PubMed – Focuses on biomedical literature, providing access to research articles, reviews, and clinical studies.
- Wolfram Alpha – A computational search engine that provides answers to factual queries, calculations, and data analysis.
Professional services
- Behance – A search engine for creative professionals showcasing their portfolios in design, photography, and art.
- CodeSearch – Aims to help developers find open-source code for their projects.
[Read also: How Can Your Business Make Use of Search Engine? Exploring Custom Solutions]
Search engines statistics
Some might say that the importance of search engines in 2024 is fading away. After all, we are living in the age of AI and Social Media behemoths and get most of our info from there.
But that’s not true.
According to the latest data, 53% of website traffic still results from organic searches and search engines still drive 300% more traffic to sites than social media. The global search engine market size was USD 167020 million in 2021 and is projected to reach USD 477029 million by 2031. I guess Google isn’t going anywhere anytime soon.
And what about of custom, specialized search engines?
According to the latest research custom search engines handle an estimated 63,000 search queries on average per second indicating their powerful software architectures. As of 2023, the search market is poised to undergo a massive shakeup due to the launch of several AI-powered search tools that enable users to search for information in a conversational setting. We will have yet to see the true results of this massive shift but in 2024 we are bound to see some major advancements in the area of AI in the search engine industry.
Work with professionals
Let’s face it – custom and meta search engine development is no easy feat.
Unlike more straightforward programming projects, search engine development requires expertise in web crawling, data indexing, algorithm development, machine learning, and user interface design, among other areas.
Each of these areas presents its own set of challenges and complexities, making the overall task of building a search engine quite daunting.
Working with custom software development professionals can greatly streamline the process of building a custom search engine, bringing expertise and efficiency to each stage of development.
These professionals have the technical skills to handle the complexities of search algorithms, data indexing, and large-scale system design, ensuring that your search engine is not only functional but optimized for speed, relevance, and scalability.

Conclusion
In summary, building a search engine is a meticulous amalgamation of sophisticated algorithms, data management, and user interface design, each of which plays a critical role in delivering accurate and relevant search results.
Hiring developers with the necessary experience and expertise is paramount to ensuring that the complexities of web crawling, data indexing, and algorithm development are handled with expertise and precision.
Ensuring continuous refinement and updates post-development will further enhance the search engine’s effectiveness and user satisfaction, solidifying its utility and reliability in the digital space.
Related Posts
Thank you for taking the time to read our blog post!
{kind=link}
{kind=link}